
Category Archives: software engineering
Javascript Things of Note
Comments Off on Javascript Things of Note
Filed under software engineering
I wish I had this Python video sooner
Video recommendation: Stop Writing Classes
Comments Off on I wish I had this Python video sooner
Filed under software engineering
Just what I’ve been needing: runipy
https://github.com/paulgb/runipy
perfect fit with my workflow and the current IHME cluster configuration.
Comments Off on Just what I’ve been needing: runipy
Filed under software engineering
New blog of possible interest
Date: Tue, 9 Feb 2016 17:45:58 +0000
From: Avi Pfeffer
To: “probabilistic-programming@lists.csail.mit.edu”
Subject: [Probabilistic-programming] New probabilistic programming
blog
Hi all,
I’ve started a blog on ideas in probabilistic programming, written for a general audience. I’ve you’d like to see the kinds of things I’m thinking about, please check it out at https://avipfeffer.wordpress.com/ .
Thanks,
Avi
+ + + + + + + + + + + + + +
Avi Pfeffer, PhD
Principal Scientist
Charles River Analytics
Comments Off on New blog of possible interest
Filed under software engineering
How we can assign multiple selections to variables when mapping data for SmartVA-Analyze 1.1
Dear ,
Thank you for your interest in this work. I have an easy answer for your second question: for anything that is a “select multiple” question (see the “type” column of the “survey” sheet in the xls form), you can encode multiple selections as a space-separated list, i.e “1 2” for cigarettes and pipe.
Here is where to look to find out if a question is a “select multiple” in PHMRC_Shortened_Instrument_8_20_2015.xls for when this comes up with other questions:
![]()
(This already came up with a different group mapping injuries, see here if you want to know more: https://healthyalgorithms.com/2016/01/28/injuries-query-on-mapping-data-for-smartva-analyze-1-1/ )
In order to answer your first question, I think I need more information. Can you give me an example of what you are trying to do? It also be helpful if you can try it, and let me know what goes wrong if it does not work.
–Abie
Comments Off on How we can assign multiple selections to variables when mapping data for SmartVA-Analyze 1.1
Filed under software engineering
agedays column in SmartVA data
Here is another little detail for the detail-oriented mapper who is trying to get data into SmartVA-Analyze: agedays.
In the tutorial, I mentioned that there are handful of additional columns that are not in the Guide, because they are created automatically by the ODK form.
The one called agedays is a bit important, because it gets used to determine if the age of the deceased is above or below a threshold. So set it! The important things currently are if it is more or less than 300 and if it is more or less than 3.
Comments Off on agedays column in SmartVA data
Filed under software engineering
Git says this is binary and it is not
I had an annoying little issue, where git was saying my file was binary. What do I care what git thinks? Well, I care if it refuses to show me my diff:
[abie@cluster-dev TICS]$ git diff
diff --git a/etl.py b/etl.py
index 3b5b4ca..2cb591e 100644
Binary files a/etl.py and b/etl.py differ
Google and Stack Overflow usually solve any problem I have like this, but today they under-delivered. They gave me a good hint, there must be some funny character in my .py file. That can happen when a 1.5 year old is helping with the typing.
Here is a quick fix, in case I (or you) ever find ourselves in this situation again:
import unidecode
f = file('etl.py').read()
with file('etl.py', 'w') as f2:
f2.write(unidecode.unidecode(f))
All better. Thanks again unidecode.
Comments Off on Git says this is binary and it is not
Filed under software engineering
Injuries Query on Mapping Data for SmartVA-Analyze 1.1
In [previous post] …
Follow-up tip:
From: Abraham D. Flaxman
Sent: Wednesday, December 30, 2015 5:16 PM
Subject: RE: VA Data Update
Cool, it looks like you are making progress. I do again encourage to do this work incrementally. So make a mapping that just gets the age and sex into the right columns and run that through, and then add in a few questions at a time to make sure things keep changing in a way that makes sense (i.e. when you add the column on chest pain to your mapping, the number of heart attack deaths should increase…).
You had a question about injury coding in your spreadsheet. Here is the coding:
1. Road traffic crash/ injury
2. Fall
3. Drowning
4. Poisoning
5. Bite or sting by venomous animal
6. Burn/Fire
7. Violence (suicide, homicide, abuse)
11. Other injury, specify (__________)
8. Refused to answer
9. Don’t know
If multiple injury causes were endorsed, you may record them as a space-separated list, i.e “2 3” for a fall that resulted in drowning.
–Abie
Comments Off on Injuries Query on Mapping Data for SmartVA-Analyze 1.1
Filed under software engineering
Mapping Data for SmartVA-Analyze 1.1
I have just released an updated version of the SmartVA app that predicts the underlying cause of death from the results of verbal autopsy interviews (VAIs). It was a lot of hard work and I hope that people find it useful. You can find the details here: http://www.healthdata.org/verbal-autopsy/tools
There is a major challenge in using this tool (now called SmartVA-Analyze 1.1), however, which is getting the necessary data to feed into it. If you use the ODK form to collect data in just the right format, it is easy. But electronic data collection is not always possible. And there is a fair amount of data out there that has already been collected, but not yet analyzed (which is some of the motivation for creating this tool in the first place).
This blog describes the process of mapping existing VAI data into a format that can be used as input to SmartVA-Analyze 1.1. It is a challenging process that requires careful attention to detail. I will demonstrate the basics here, and I hope to provide fuller examples in multiple scripting languages as researchers complete this exercise for themselves.
A short version of the following, with example code is available on GitHub: https://github.com/aflaxman/SmartVA-Analyze-Mapping-Example
The ODK output of electronic version of the PHMRC Shortened Questionnaire is a .csv file, such as the following: https://github.com/aflaxman/SmartVA-Analyze-Mapping-Example/blob/master/example_1.csv
But if you have data that was collected with pencil-and-paper and then laboriously digitized, you will need to map it into that format. This Guide for data entry spreadsheet is your Rosetta Stone. SmartVA-Analyze 1.1 expects the input csv file to have a column for every row in that spreadsheet, with column heading matching the entry in the “field name” column.

I like to use Python with Pandas for doing this kind of work, but I recommend you use whatever scripting language you are most comfortable with. But I strongly recommend that you use a script to do this mapping. It will be much easier to debug and reproduce your work than if you do the mapping by hand! (I also recommend that you work incrementally and use a revision control system…) To learn more about the Python/Pandas approach, I recommend the book Python for Data Analysis.
Here is a block of Python code that will create a DataFrame with columns for every field named in the Guide:
import numpy as np, pandas as pd # load codebook fname = 'https://github.com/aflaxman/SmartVA-Analyze-Mapping-Example/raw/master/Guide%20for%20data%20entry.xlsx' cb = pd.read_excel(fname, index_col=2) df = pd.DataFrame(index=[0], columns=cb.index.unique())
(you can also see this in context in an Jupyter Notebook on GitHub here.)
SmartVA-Analyze 1.1 requires a handful of additional columns that are not in the Guide (they are created automatically by the ODK form): child_3_10, agedays, child_5_7e, child_5_6e, adult_2_9a. Here is a block of Python code that will add these columns to the DataFrame created above:
df['child_3_10'] = np.nan df['agedays'] = np.nan # see notes though http://wp.me/pk40B-Mm df['child_5_7e'] = np.nan df['child_5_6e'] = np.nan df['adult_2_9a'] = np.nan
If you save this DataFrame as a csv file, it will constitute a minimal example of what is necessary to make SmartVA-Analyze 1.1 run:
fname = 'example_1.csv' df.to_csv(fname, index=False)
Here is what it looks like when SmartVA-Analyze 1.1 is running:
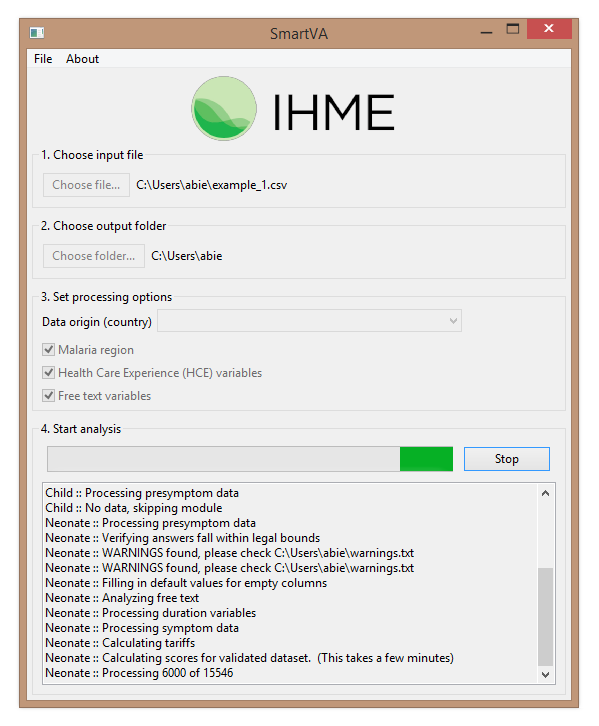
The results are rather minimal, and can be found in the “neonate-predictions.csv” file (because without an age or age group specified, this is the default):

Mapping a more substantial dataset, even a the following hypothetical example is an idiosyncratic and time-consuming procedure.
Example (hypothetical) dataset:

Python code to map the id, sex, and age:
# set id
df['sid'] = hypothetical_data.index
# set sex
df['gen_5_2'] = hypothetical_data['sex'].map({'M': '1', 'F': '2'})
# set age
df['gen_5_4'] = 1 # units are years
df['gen_5_4a'] = hypothetical_data['age'].astype(int)
This is the simple stuff… to map the injury data you will need to dig into the paper questionnaire to see how the responses are coded (the Guide spreadsheet includes some codings, but will refer you to the paper questionnaire when necessary):
# map injuries to appropriate codes
# suffered injury?
df['adult_5_1'] = hypothetical_data['injury'].map({'rti':'1', 'fall':'1', '':'0'})
# injury type
df['adult_5_2'] = hypothetical_data['injury'].map({'rti':'1', 'fall':'2'})
Mapping more columns proceeds analogously, but I recommend working incrementally, so at this point you should save the partially mapped data and make sure it runs through the SmartVA-Analyze app, and make sure that the results make some sense. For example, in this case the mapped hypothetical data from the first 2 rows are correctly identified as traffic and fall injury deaths, but the final 3 rows are undetermined (because non-injury signs and symptoms have not yet been mapped).
Mapping the additional columns proceeds analogously:
# map heart disease (to column adult_1_1i, see Guide)
df['adult_1_1i'] = hypothetical_data['heart_disease'].map({'Y':'1', 'N':'0'})
# map chest pain (to column adult_2_43, see Guide)
df['adult_2_43'] = hypothetical_data['chest_pain'].map({'Y':'1', 'N':'0', '':'9'})
I hope that this helps… if you’ve read this far, you probably have a hard job ahead of you! Please see the Jupyter Notebook version of this example here, and good luck!
Filed under software engineering
Fake git manual that could be real
Comments Off on Fake git manual that could be real
Filed under software engineering
