
I learned about an interesting book today, The Architecture of Open Source Applications, edited by Amy Brown and Greg Wilson. The introduction caught my attention:
Architects look at thousands of buildings during their training, and study critiques of those buildings written by masters. In contrast, most software developers only ever get to know a handful of large programs well—usually programs they wrote themselves—and never study the great programs of history. As a result, they repeat one another’s mistakes rather than building on one another’s successes.
This book’s goal is to change that. In it, the authors of twenty-five open source applications explain how their software is structured, and why. What are each program’s major components? How do they interact? And what did their builders learn during their development? In answering these questions, the contributors to this book provide unique insights into how they think.
If you are a junior developer, and want to learn how your more experienced colleagues think, this book is the place to start. If you are an intermediate or senior developer, and want to see how your peers have solved hard design problems, this book can help you too.
There are chapters on several software packages that I’ve enjoyed using, and chapters on several scientific/data analysis tools, but nothing on the tools I’m using day to day. Still interesting. Let me know if there is a great chapter you come across, since I’m going to be too busy to read the whole thing in the near future.
 , I’ll make a quick blog post about verifying this claim numerically (in python with networkx). This also gives me a chance to try out the new networkx, which is currently version 1.0rc1. I think it has changed a bit since we last met.
, I’ll make a quick blog post about verifying this claim numerically (in python with networkx). This also gives me a chance to try out the new networkx, which is currently version 1.0rc1. I think it has changed a bit since we last met.
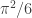 .
. 
 A couple of weeks ago, I mentioned the exciting experiment in online math collaboration, where Tim Gowers invited the world to set out and develop a combinatorial proof of the density Hales-Jewitt theorem (DHJ). Big congratulations to them, because
A couple of weeks ago, I mentioned the exciting experiment in online math collaboration, where Tim Gowers invited the world to set out and develop a combinatorial proof of the density Hales-Jewitt theorem (DHJ). Big congratulations to them, because 

