(This is a post that I started a long time ago (Aug 10, 2010), but hung on to because it is only half-baked. But based on the philosophy that avoiding foolishness is a recipe for silence, I’m sending it out into the world. Coming next: the simplest useful open problem in DCP optimization.)
Acronyms are like candy in Global Health, and Operations Research is full of them, too. This post is a place for me to collect information about software available for solving the Mixed Integer Programming (MIP) problem that the Disease Control Priorities (DCP) project is going to put together.
DCP is a massive effort to quantify the cost-effectiveness of hundreds of health interventions across tens of “health platforms” (big hospitals, small clinics, pharmacies, etc). The output of this large, coordinated effort will be (as far as I’m concerned) a collection of giant matrices, that say, for different subsets of interventions across different platforms, (1) the cost of setting up the interventions, (2) the cost of operating the interventions, (3) the health gain from the interventions. Undoubtedly, there will be some quantification of the uncertainty in each of these quantities. Also, there is something called platform improvement, which can be thought of as a special type of intervention that makes a bunch of other interventions more effective on a certain platform. And there are a number of side-constraints; some interventions come together on certain platforms, some interventions are mutually exclusive, etc.
Some unknowns: (how) will the uncertainty in the entries of these matrices be quantified? Are the intervention choices all “yes/no” or do you choose how much you want of some of them, i.e a non-negative continuous variable?
This is the optimization that mixed integer programming was born for (except for the uncertainty, which takes us into less charted waters). So how we are going to do it, in theory, is just the sort of thing my OR classes focused on when I was in grad school. We didn’t talk much about how to do it in practice. Some of the hard-working students who sat in the business school and actually solved large integer programs would mutter about CPLEX once in a while at parties, but I didn’t pay it much heed.
Heed I must now pay. So I am collecting up the available MIP solvers here, and (eventually) evaluating them for my DCP optimization task. Got suggestions? I would love to hear them.
- Gurobi – 1 2 3
- ILOG/CPLEX – 1 2
- GAMS – 1
- AMPL – 1
- NEOS – 1



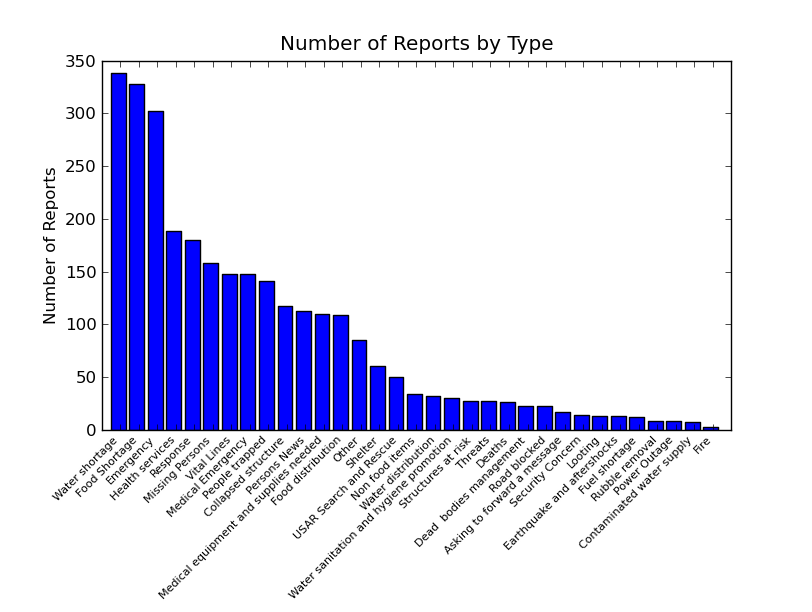

 , I’ll make a quick blog post about verifying this claim numerically (in python with networkx). This also gives me a chance to try out the new networkx, which is currently version 1.0rc1. I think it has changed a bit since we last met.
, I’ll make a quick blog post about verifying this claim numerically (in python with networkx). This also gives me a chance to try out the new networkx, which is currently version 1.0rc1. I think it has changed a bit since we last met.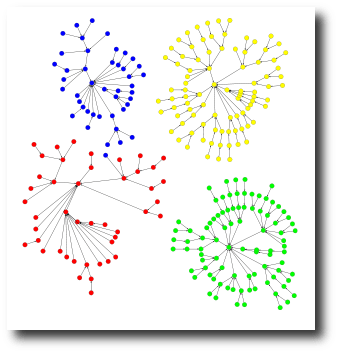 I’m updating my CV, and that reminded me that I meant to promote this cool clustering technique that I was a little bit involved in,
I’m updating my CV, and that reminded me that I meant to promote this cool clustering technique that I was a little bit involved in, 