There are lovely libraries near my house. Three, all in different directions. I have spent hours in each, especially before my kids were in school. This is a story is about the one called the Douglass-Truth Library, the surprising way it got that name, and a computer simulation inspired by that surprise. Maybe it will surprise you, too.
The Douglass-Truth Library. Its name stands out from its peers. They have names like “Beacon Hill Library” and “Central Library”. Most Seattle libraries are named to match their neighborhoods.
Not the Douglass-Truth Library. We just celebrated the 50th anniversary of its renaming. It was renamed in 1975 to honor the abolitionists Fredrick Douglass and Sojourner Truth. And how were these particular leaders selected for this honor? A community vote!
Back in the early 1970s, community leaders in a neighborhood that had become predominantly African American thought their library deserved a name that reflected the community. They organized a ballot listing ten distinguished Black Americans and invited the neighborhood to vote.
The ballot clearly says “vote for one”.
How did the library get named after two?
A tie vote! Out of a ten-person race.
That is so unlikely. Is it so unlikely? How unlikely?
When I slow down to think about it, I think it must depend on how many votes there were. One hundred voters tying does not seem likely, but it seems more likely than ten thousand voters ending in a tie. How many ballots were cast? I could not find any documentation of this. But when I was at the renaming anniversary party last December, someone remembered: around 2,000 people voted.
So now can we figure out how unlikely?
Almost. I used to love simplifying probability equations and making approximations for these sorts of formulas, and if I was writing this blog 25 years ago, it would be all about Stirling’s approximation and how with pencil and paper we could puzzle this out. Stirling showed that tie probability scales like , and that means 2,000 voters doesn’t give you 1-in-2,000 odds—it’s more like 1/45. Ties are rarer with more voters, but not vanishingly rare.
Lately, though, I’ve become more of a computer-simulation type. Pencil and paper is fine, but random number sampling is even more fun.
From here, I’ll give just a sketch, so you can have fun the way you like to have fun.
Assumptions: maybe the simplest way to start is if everyone is equally liked and voters are simply choosing randomly (no strategic behaviors). But would it be more likely to have a first-place tie if two front runners were each getting nearly 50% of the vote?
Simulation: With simplifying assumptions, I can simulate one person’s vote with np.random.choice(candidate_list, vote_probabilities), but it is faster to simulate everyone’s vote simultaneously. Then I need to tally the votes and see if there is a tie for first place.
returntallies.iloc[0]==tallies.iloc[1]# True if tie for first
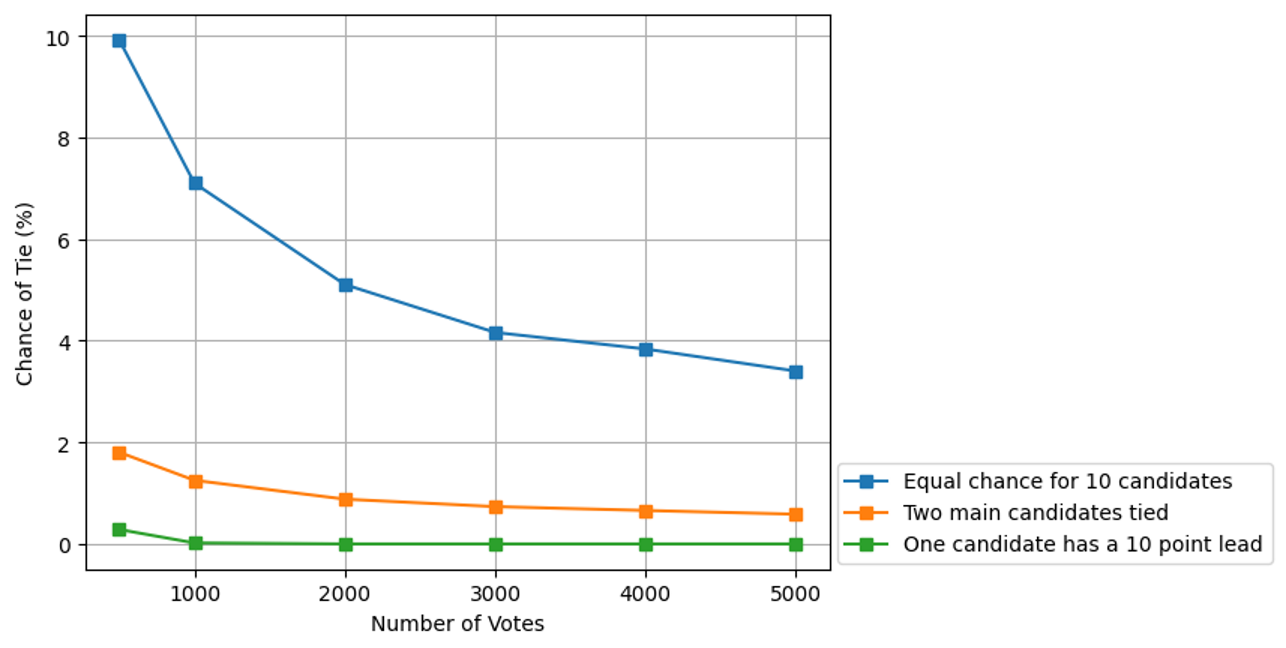
Results: If all ten candidates are equally liked, there’s roughly a 1 in 20 chance of a first-place tie (with 2,000 voters). The chances drops as turnout grows—but stays above 3% even with 5,000 voters.
If there are two front runners it is more like one in 100, and if one candidate has a comfortable majority, then a tie is extremely rare.
Conclusion: The math is fun. The computer simulation is fun. But the real breakthrough happened 50 years ago when the votes came in tied and some genius invented a new option: name the library after both heroes.
A hands-on guide to catching simulations bugs with automated tests
TL;DR
What you’ll learn: Write rigorous tests for randomized algorithms without arbitrary thresholds.
What you’ll get: A failing test that catches a subtle directional bias bug with Bayes factor = 10⁷⁹ (decisive evidence).
The approach: Run simulations many times, count outcomes, validate proportions using Bayesian hypothesis testing. The heart of this Fuzzy Checking Pattern is this method
The Problem: How Do You Test Randomized Algorithms?
Imagine you’re using computer simulation in your research, like an agent-based model or a Monte Carlo simulation. You run your code and it produces output. Then you run it again and get different output. That’s expected! It’s random. But here’s the challenge:
How do you know your “random” behavior is actually correct?
Traditional unit tests fail:
# This doesn't work - random walks vary!
assert result == 42
# Neither does this - what threshold?
assert 40 <= result <= 44
Instead of asking “is this close enough?” (with arbitrary thresholds), ask: “What’s the evidence ratio for bug vs. no-bug?”
We’ll do this with the Bayes factor:
Bayes factor > 100 = “decisive” evidence of a bug → Test FAILS
Bayes factor < 0.1 = “substantial” evidence of correctness → Test PASSES
Bayes factor between 0.1 and 100 = “inconclusive” → WARNING (need more data)
The Bug We’ll Catch
We’ll test a simple 2D random walk simulation. The walker starts at the center of a grid and takes random steps (left, right, up, down) until it reaches an edge.
Can you spot it? [0, -1] appears twice (up), and [0, 1] (down) is missing!
Impact: The walker can move left (25%), right (25%), up (50%), but never down (0%). This creates a bias that’s hard to spot with traditional asserts but shows up dramatically in statistical tests.
I have separated my simulation code (random_walk.py) from my automatic testing code (test_random_walk.py). I recommend this for you, too. The simulation does your science, the tests check if your science has bugs.
1. Write Your Simulation (in random_walk.py)
The fill_grid(grid, moves) function simulates a random walk and returns where it ended:
def fill_grid(grid, moves):
"""Fill grid with random walk starting from center."""
center = grid.size // 2
size_1 = grid.size - 1
x, y = center, center
num = 0
while (x != 0) and (y != 0) and (x != size_1) and (y != size_1):
grid[x, y] += 1
num += 1
m = random.choice(moves)
x += m[0]
y += m[1]
return num, x, y # Steps taken and final position
This method performs Bayesian hypothesis testing to validate that observed proportions match expectations:
from vivarium_testing_utils import FuzzyChecker
# Example: Validate that ~25% of walks exit at left edge
FuzzyChecker().fuzzy_assert_proportion(
observed_numerator=254, # 254 walks exited left
observed_denominator=1000, # Out of 1000 total walks
target_proportion=0.25, # We expect 25%
)
The buggy random walk exits left only 3% of the time (expected 25%):
pytest test_random_walk.py::test_buggy_version_catches_exit_bias -v
AssertionError: buggy_left_exit_proportion value 0.03 is significantly less than expected, bayes factor = 1.37e+79
That’s astronomically decisive evidence of a bug. The buggy version can move up twice but never down, so 94.6% of walks exit at the top edge, dramatically reducing other exits.
One test for the correct version (validates exit edge proportions)
One test for the buggy version (demonstrates catching the bug)
Examples of using fuzzy_assert_proportion() with exit locations
Run the tests with:
pytest test_random_walk.py
Adapting This for Your Own Work
Ready to use fuzzy checking in your own spatial simulations? Here’s how:
Step 1: Install the Package
pip install vivarium_testing_utils pytest
Step 2: Identify Statistical Properties
What should your simulation do in aggregate?
Agent-based models: “30% of agents should be in state A”
Monte Carlo: “Average outcome should be between X and Y”
Spatial sims: “Density should be symmetric when flipped horizontally or vertically”
Step 3: Write Fuzzy Tests
import pytest
from vivarium_testing_utils import FuzzyChecker
@pytest.fixture(scope="session")
def fuzzy_checker():
checker = FuzzyChecker()
yield checker
checker.save_diagnostic_output("./diagnostics") # this pattern saves a csv for further inspection
def test_my_property(fuzzy_checker):
# Run your simulation many times
successes = 0
total = 0
for seed in range(1000):
result = my_simulation(seed)
if condition_met(result):
successes += 1
total += 1
# Validate with Bayesian inference
fuzzy_checker.fuzzy_assert_proportion(
observed_numerator=successes,
observed_denominator=total,
target_proportion=0.30, # Your expected proportion
name="my_property_validation"
)
Step 4: Tune Sample Sizes
Small samples (n < 100): Tests might be inconclusive
Medium samples (n = 100-1000): Good for most properties
Large samples (n > 1000): High power to detect subtle bugs
If you get “inconclusive” warnings, increase your number of simulation runs.
A Challenge: Can You Find the Bug With Even Simpler Observations?
The tests above observe exit locations. But can you detect the bug using only the grid visit counts?
This is perhaps Greg Wilson’s original challenge: find a statistical property of the grid itself that differs between correct and buggy versions.
Some ideas to explore:
Does the distribution of visits differ between quadrants?
Are edge cells visited at different rates?
Does the center-to-edge gradient change?
What about the variance in visit counts?
Can you detect the bias without even tracking final positions?
Try implementing a test that catches the bug using only the grid object returned after the walk.
Additional Challenges: Deepen Your Understanding
Ready to experiment? Try these exercises to build intuition about fuzzy checking:
1. Sample Size Exploration
Reduce num_runs from 1000 to 100 in the directional balance test.
What happens to the Bayes factors?
Do tests become inconclusive?
How many runs do you need for decisive evidence?
2. Create a Subtle Bug
Modify the moves list to this alternative buggy version: [[-1, 0], [1, 0], [1, 0], [0, -1], [0, 1]] (two right moves instead of two up moves; this erroneous addition to the list means that the random walk has some chance to exit from each side).
Does fuzzy checking catch this subtler bias?
How does the Bayes factor compare to the up/down bug?
What does this reveal about detection power?
3. Validate New Properties
Write a new test that validates:
The center cell is visited most often
The walk forms a roughly circular distribution
The total path length scales as (grid size)²
Hint: For the center cell test, compare grid[center, center] to the average of edge cells using fuzzy_assert_proportion().
Testing stochastic simulations doesn’t have to rely on arbitrary thresholds or manual inspection. Bayesian fuzzy checking provides a rigorous, principled approach:
✅ Quantifies evidence with Bayes factors ✅ Expresses uncertainty naturally ✅ Catches subtle bugs that traditional tests may miss
The vivarium_testing_utils package makes this approach accessible with a simple, clean API. Whether you’re testing random walks, agent-based models, or Monte Carlo simulations, fuzzy checking helps you validate statistical properties with confidence.
What About More Complex Simulations?
This tutorial used a simple random walk where tracking direction counts was straightforward. But what about more complex spatial processes?
Greg Wilson’s blog post includes another example: invasion percolation, where a “filled” region grows by randomly selecting neighboring cells to fill next. The grid patterns are much more complex than a random walk.
How would you test that? What statistical properties would you validate? How would you instrument the code to observe the right quantities?
This tutorial was created to demonstrate practical statistical validation for spatial simulations. The fuzzy checking methodology was developed at IHME for validation and verification of complex health simulations.
Comments Off on Testing Stochastic Simulations: Bayesian Fuzzy Checking in Python
It is fun to get a social feed again, but I’ve got some curating to do — I’ve got a lot of interesting people to follow, but not a lot of science peers to interact with. I guess that took me about 15 years to build on twitter.
One thing about my feed at this point is that there is a lot of AI-skeptic content in my feed. I’m always interested, but it does not quite match my experience. I will be the first to say that Generative AI is bullshit (in the philosophical sense), but BS can be useful some times. And preparing for interviews is one of those times.
If you are a scientist and have to talk to the media, I hope you have some strategies for this already. If you want to practice for this interview and you don’t have someone to practice with, try asking your chatbot to pretend to be an interviewer. Here is a prompt I’ve used in my own preparations.
“Please help me prepare to provide an interview to a journalist about X. You play the role of the journalist and ask me questions, which I will provide answers to for you. Some example questions are: Y, Z, W”
Coding and testing when you know what you want the computer to do
Reminder of Intro and Debugging 1 & 2: AI is BS, but not useless; You can prompt it with an error message and get suggestions, you can give it an example of code that is not doing what you think it should do. Tell it who you want it to be and keep asking questions if necessary.
Next idea: If you have not written the code, if you know what you want it to do, you can ask a chatbot to write it for you.
This works particularly well with functions. Example, a function for the SEIR model in a closed cohort, start with:
Don’t know just how to test? A chatbot can help with that, too, e.g. prompt of how can I test fx_seir to make sure it is doing what I want?
You can write the tests first (“test-driven development” is the name for this in software engineering); this turns the process of writing code into a game (and if you like this game, you might be a software engineer!)
Lauren Wilner (Epi 560 TA) says: Try to use AI to help you build on things you already know. For example, if you are told to write a loop but you already know how to do what you want to do by copying and pasting 10 times, write out the code you would write (in 10 lines with copy and pasting and changing little things) and then ask ChatGPT to give you advice on putting it into a loop. That way, you can run your code both using what you wrote and what ChatGPT gave you.
Lauren Wilner (Epi 560 TA) says: for testing code I have found that ChatGPT is very good at simulating data. I will often simulate my own data, write a function, and at the point I think that I’m done, I will give my function to ChatGPT and tell it to simulate data with whatever parameters I am using and see if it is able to replicate my work. This isn’t relevant for our students necessarily, but I do think it is very helpful – it acts sort of like a second pair of eyes.
Understanding, explaining, and documenting code(aka “what is this doing?”)
Reminder of Intro and Debugging 1 & 2: AI is BS, but not useless; You can prompt it with an error message and get suggestions, you can give it an example of code that is not doing what you think it should do. Tell it who you want it to be and keep asking questions if necessary.
Final idea: How to ask an AI to explain code. You can use this to help yourself understand code in the assignments, and you can even use it to document your code to help others, including your future self, understand your code.
For example, “Explain this code:
# Call lsoda function with initial conditions, times, SIR function, and parameters defined above.
output = pd.DataFrame(lsoda(y=init, times=t, func=fx_sir_bd, parms=params))
Lauren Wilner (Epi 560 TA) says: start prompt according to first precept, e.g. “Can you please pretend to be my stats professor and explain to me what the code below is doing and what the expected output is and what this code would be used for? Are there things you would change or improve?”
Keep asking questions if necessary!
Lauren Wilner (Epi 560 TA) says: If I inherit code, I generally ask ChatGPT to comment each line or function or code chunk with what it is doing and have found that very helpful.
You can also ask it to document or improve documentation in code you have written (or received).
For example, “Please improve the documentation in this code:
Lauren Wilner (Epi 560 TA) says: an additional prompt for this might be: “Can you please pretend to be my mentor and explain to me what the code below is doing and what the expected output is and what this code would be used for? Are there things you would change or improve?”
Lauren Wilner (Epi 560 TA) says: I love giving ChatGPT my code that I have finished and asking it to tell me what my code is doing. This both helps me with documentation as well as ensures that the code I wrote is doing what I think it is doing. If ChatGPT tells me something surprising about what my code is doing, I generally start a conversation saying “I thought I was doing X, can you explain to me why you think I am doing Y? Am I also doing X?” or something like that.
Debugging 2: When the code does not fail, but still is wrong
Reminder of Intro and Debugging 1:AI is BS, but not useless; Prompt with error, get suggestions, keep asking, if necessary.
This time, what if there is no error, but something is wrong?
Create a MCVE (minimal complete verifiable example), possibly including a screenshot
Describe the issue to a ChatBot, and keep iterating if necessary. (This will be necessary more often than for Debugging when Code Fails, because then you have an error message to work with!)
The anatomy of an MCVE (follow link for more detail):
Minimal: Use as little code as possible that still produces the same problem
Complete: Provide all parts someone else needs to reproduce your problem in the question itself
Reproducible: Test the code you’re about to provide to make sure it reproduces the problem
Remember the first precept of prompt engineering: Tell AI who you want it to imitate e.g. “You are a friendly and expert teaching assistant.”
Lauren Wilner (Epi 560 TA) says: I advise the students to tell ChatGPT something like: “Please pretend to be my TA who I go to when I have trouble with my coding in my Data Management class. I am coding in R, and she helps me by giving me tips on rewriting my code and gives me sample lines of code I can use and ensure they do what I want. She also tells me how to know whether the code that she gave me is doing what I expected. The code I am working does X. Currently, I have the following lines of code: Y. Can you please help me rewrite this into a loop?”
Watch out for a common pitfall with BS Bots! Lauren Wilner says, “I find that if I ask ChatGPT what is wrong with something or how something can be improved or whether something is X, it will never say “looks good” or “no problems” or “no improvements needed” – it will always make some change or update. Sometimes that update makes things worse! So, overuse can be an issue.
“Again, it comes back to knowing what you expect or want to see and using ChatGPT to assist you and not do things for you.”
In summary: AI is BS, not useless; Useful for debugging; don’t stay stuck for long, prompt with MCVE code example, and polite request for help. Keep convo going if necessary.
Following up on the general guidance I offered Epi 554 last week, this week I tried to get specific about how to use AI assistance in debugging. I think there is room for improvement, but I’m going to get it out to you, and maybe you’ll tell me how to improve.
Debugging 1: When the code fails
Maybe I’ve told you that AI is BS. But that doesn’t make it useless.
Useful for debugging: use it so that you don’t stay stuck for long example: error in code from Lab 2, shown below:
(if you know how to fix this… don’t worry you’ll have an error msg that is less obvi soon; and if you are above-average in debugging… this approach might make you worse!)
Teach an advanced AI technique called “Prompt Engineering“, example: paste error, type “why?” — aside: be polite in your prompts, for a better world and for better answers. Let’s not go through the details of the answer in detail — I want to focus on how and when to ask
You can be more verbose, e.g. you can explain what you were trying to do, paste your error, and ask why you got this error and if it has ideas on how to fix the error that you got.
You can also use the first precept of prompt engineering: tell AI who you want it to be. e.g. “You are a friendly and expert teaching assistant.” or “You are a busy and distracted professor.” (?)
Customize as preferred, e.g. if appropriate, you can start with “you answer in English, but you know that I speak Spanish as a native and English is not my first language.”
You try: here is an error to work with [[I didn’t actually come up with this]], and an answer that still doesn’t fix it. What might you ask next?
Lauren Wilner (Epi 560 TA) says: For debugging, I have found that ChatGPT is mediocre. I give it the code I ran and the error I got, generally, but I find that often it gives me either (1) code that has the same error again or (2) new code that has a different error.
Summary: AI is BS, not useless; Useful for debugging; don’t stay stuck for long, prompt with code example, and polite request for help. Keep convo going if necess. It is just imitating the way words often hang together in online text, like stack overflow and cross validated, but if it gets your code to run… then you have running code!
I offered students in Introduction To Epidemic Modeling For Infectious Diseases some general guidance on using AI this week, and I thought I’d share it more broadly. We are going to get into specifics for AI-assisted coding over the next few weeks, because that is one area where I think this stuff might really help them in this course.
Introduction to Generative AI in Epi 554
Not magic — “just” next word prediction
But it is next word prediction so good that it keeps me up at night, like in existential crisis
How does it do it? Statistical language model — a conditional probability distribution
This is the platonic ideal of the philosophical notion of “bullshit”
BS does not mean useless; it can be useful! For somethings… but…
Studies have found that AI is good for helping people with average-to-poor skills in an area attain slightly-above-average performance — so what are you average-to-poor at???
Prof Steve Mooney says: for 554 (and all classes), the only point of doing coursework is to learn what you’re doing. If you learn to use AI to help you code in general, great! That’s a useful skill. BUT if you only learn to use AI to help you complete this coursework, it’s like you just overfit your model – you can’t project forward usefully with it. So, your proper focus ought to be on how AI helps you avoid busywork/debug faster/more deeply understand what you’re doing, not just how to get done sooner.
ChatBots can help you build on your existing skills. Lauren Wilner (Epi 560 TA) says: I find ChatBots useful for things that are at the edge of what I know. That is slightly different, I think, than areas where I have average-to-poor skills.
I will be demonstrating its use through ChatBots and not through coding assistants (like GitHub co-pilot); I think this is best matched to this class, but I’m still learning!
Take responsibility. Lauren Wilner (Epi 560 TA) says: I know it sounds obvious, but I would emphasize that they need to read and edit what ChatGPT or other AI tools give them. A lot of them seem to skip that step and trust it blindly, and I would strongly remind them that they need to use it for advice and feedback, not for answers.
Don’t hide it. Lauren Wilner (Epi 560 TA) says: The students who are the most transparent with me in office hours or elsewhere in terms of where they are stuck, what they asked ChatGPT, and why they are still stuck, are the students that I find to be the most successful. The students who hide their use of AI struggle more because they often don’t really understand what they are doing. Whatever you can do to create a welcoming environment in terms of AI tools but also a cautionary tale that they can’t just give you straight ChatGPT output, the better results I think you will have!
Build on what you know. Lauren Wilner (Epi 560 TA) says: Try to use AI to help you build on things you already know. For example, if you are told to write a loop but already know how to do what you want to do by copying and pasting 10 times, write out what you would do and then ask ChatGPT to give you advice on putting it into a loop. That way, you can run your code both using what you wrote and what ChatGPT gave you.
For the last year, I have been a faculty advisor for the START Center at UW, which gives students an opportunity to do consulting projects, mostly in global health, mostly for the Gates Foundation.
Since I have also been obsessed with the opportunities and threats of generative AI for the last year, it was only a matter of time before I developed some opinions about how these students might use chatbots in their work.
I thought I’d share them here as well, lightly edited:
Thoughts on how START should be using AI
Abraham D. Flaxman, 2024-07-12
(15 minutes for synopsis and discussion)
Should START be using AI?
Gates Foundation (and Bill Gates) very optimistic about value of recent AI breakthroughs
“Generative AI” – new term for the things people are excited about, e.g. ChatGPT
GenAI changing fast – if you checked in when you first heard about it, it is time to check again
Generative AI is bullshit* *in the technical, philosophical sense
Not magic — “just” next word prediction
But it is next word prediction so good that it keeps me up at night, like in existential crisis
Uses relevant to START projects:
Use anywhere you would use BS* *in the technical, philosophical sense
AI-assisted coding, e.g. creating visual representations of quantitative information
Ideation (brainstorming) – “Come up with 20 ideas for X”
Editing – “Can you provide a suggested edit that follows the style guidelines of Strunk & White?”
Explanation – “Can you rephrase that so a fifth grader would understand it?”
Studies have found that AI is good for helping people with average-to-poor skills in an area attain slightly-above-average performance — so what are we average-to-poor at?
Summarization – “What were the findings?”
Specific translation tasks, such as
For non-native English speakers – “Write a professional email expressing these points in English”
For specific terms – “What does “sueños blancos” mean in English?”
ChatBots can help you build on your existing skills. Lauren Wilner (Epi 560 TA) says: I find ChatBots useful for things that are at the edge of what I know. That is slightly different, I think, than areas where I have average-to-poor skills.
Other ideas?
Ethical principles:
Take responsibility. Lauren Wilner (Epi 560 TA) says: I know it sounds obvious, but I would emphasize that they need to read and edit what ChatGPT or other AI tools give them. A lot of them seem to skip that step and trust it blindly, and I would strongly remind them that they need to use it for advice and feedback, not for answers.
Don’t hide it. Lauren Wilner (Epi 560 TA) says: The students who are the most transparent with me in office hours or elsewhere in terms of where they are stuck, what they asked ChatGPT, and why they are still stuck, are the students that I find to be the most successful. The students who hide their use of AI struggle more because they often don’t really understand what they are doing. Whatever you can do to create a welcoming environment in terms of AI tools but also a cautionary tale that they can’t just give you straight ChatGPT output, the better results I think you will have!
Some of the example prompts above are from Jeremy N. Smith, You, Me, and AI presentation, http://jeremynsmith.com/
Notes on what I should add to this, based on discussion with other START faculty last week:
A section on educational resources and observations, including the pernicious effect of chatbots on student question-asking; the cool exercises that a history prof came up with, where the educational task was identifying what was truth and what was fiction in chatbot generated text; invite-AI-to-the-table ideology — have a chatbot ask questions during class??
START students often conduct interviews with Key Informants; they could practice this ahead of time with a chatbot
With more time, I should include some real examples of where AI has been useful and not useful, such as:
Not so good: generating a summer reading list about feminist approaches to cost-effectiveness analysis (most of the suggested papers do yet exist yet!)
Comments Off on Some thoughts on how epidemiology students might use AI
When I was preparing to teach my Fall course, I was concerned about AI cheaters, and whether my lazy approach to getting students to do the reading would be totally outdated. I came up with a “AI statement” for my syllabus that said students can use AI, but they have to tell me how they used it, and they have to take responsibility for the text they turn in, even if they used an AI in the process of generating it.
Now that the fall quarter has come and gone, it seems like a good time to reflect on things. On third of the UW School of Public Health courses last fall had AI statements, with 15 saying “do not use” and 30 saying use in some way (such as “use with permission”, or “use with disclosure”).
In hindsight, AI cheating was not the thing I should have been worrying about. Here are five areas of concern that I learned about from my students and colleagues that I will be paying more attention to next time around:
1. Access and equity – there is a risk with the “pay to play” state of the technology right now. How shall we guard against a new digital divide between those who have access to state-of-the-art AI and those who do not? IHME has ChatGPT-4 for all staff, but only the Health Metrics Sciences students who have IHME Research Assistantship can use it. As far as I can tell, the Epi Department students all have to buy access. From what I can tell, the University of Michigan is solving this, are other schools?
“When I speak in front of groups and ask them to raise their hands if they used the free version of ChatGPT, almost every hand goes up. When I ask the same group how many use GPT-4, almost no one raises their hand. I increasingly think the decision of OpenAI to make the “bad” AI free is causing people to miss why AI seems like such a huge deal to a minority of people that use advanced systems and elicits a shrug from everyone else.” —Ethan Mollick
2. Interfering with the “novice-to-expert” progression – will we no longer have expert disease modelers, because novice disease modelers who rely on AI do not progress beyond novice level modeling?
4. Implicit bias – language models repeat and reinforce systems of oppression present in training data. How can we guard against this harming society?
5. Privacy and confidentiality – everything we type into an online system might be used as “training data” for future systems. What are the risks of this practice, and how can we act responsibly?
Comments Off on Five areas of concern regarding AI in classrooms