
Inspired by the recent 8F workshop, I’m trying to write up theory challenges arising from global health. And I’m trying to do it with less background research, because avoiding foolishness is a recipe for silence.
This is the what I called the “simplest open problem in DCP optimization” in a recent post about DCP (Disease Control Priorities), but with more reflection, I should temper that claim. I’m not sure it is the simplest. I’m not sure it is an open problem. And I’m pretty sure that if we solve it, the DCP optimizers will come back with something more complicated.
But it is a nice, clean problem to start with. I’m calling it “Fully Stochastic Knapsack”. It looks just like the plain, old knapsack problem:
The fully stochastic part is that everything that usually would be input data is now a probability distribution, and the parameters of the distribution are the input data.
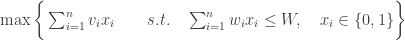
This makes even deciding what to maximize a challenge. I was visiting the UW Industrial Engineering Dept yesterday, and Zelda Zabinsky pointed me to this nice INFORMS tutorial by Terry Rockafeller on “coherent approaches” to this.

Nice tutorial, thanks.
Here’s a 2009 paper related to your problem, rejoicing in the name of “The Submodular Knapsack Polytope” – http://ieor.berkeley.edu/~atamturk/pubs/subknap.pdf
Why not generate many realizations of the knapsack problem using the value distributions then solve that ensable of solutions with a two-stage stochastic MIP model?
@Carleton: I love reducing a problem to an “already solved problem”, but in this case I don’t follow you. What would the stages be?
@Carleton wrote up some thoughts on this, and said I can post them here, to continue the discussion in public.
My thoughts on these notes are the following:
In Section 3, I’m happy to have strong assumptions about the joint distribution. Independent and normally distributed with known mean and standard deviation should be a fine start, and independent mixtures of two normals with the same mean should be flexible enough for anything my colleagues can come up with. This doesn’t answer the question of how many samples are needed, but it does make it a much more specific question.
In Section 4, due to the large amount of uncertainty I expect in the input data, I expect that the robust programming formulation will not yield useful information. It would still be an interesting number to have for comparison, however, especially if it turns out to have the same or similar optimal solution as the richer formulation.
In Section 5, I’m starting to see now what you had in mind when you suggested I use a two-stage formulation. Very sneaky! If I’m reading it correctly, there are a few typos: the objective (equation (16)) should have instead of just
instead of just  , there should not be a
, there should not be a 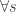 in equation (18) and the
in equation (18) and the  values in equations (19) and (20) need superscripts. Then the optimal point for
values in equations (19) and (20) need superscripts. Then the optimal point for  will tell us the set of interventions to consider buying, while the sum
will tell us the set of interventions to consider buying, while the sum  tells us the probability that this intervention is not included in the optimal solution.
tells us the probability that this intervention is not included in the optimal solution.
A big question for me is what is lost by the linear relaxation you propose.
In answer to your questions:
I think that maximizing the expected health gain is fine, and it is the constraints that might be better to “soften”, i.e. instead of saying the the expected superset is within the budget, say something like the probability of exceeding the budget is less than 10%, and we will never exceed it by more than 10%. As the above paper by Rockafeller points out, there is no technical distinction between the objective and the constraints, so this is purely application specific.
As for the number of samples, if we start with independently distributed normals, can you figure out how many are needed in that case?
Regarding the sampling, this makes a lot of sense, although I have an intuition that there are certain “worst-case” scenarios that we should be looking for, like when an unusual set of things are all off, e.g. when v_i and w_i both happen to be large.
I haven’t kept up with the online set cover business, although it looks like it has been quite a healthy area of inquiry in recent years. Maybe some other reader will know how this overlaps.
@Abraham: I updated the document to fix the typo’s you mentioned and also also added a Section 6 which discusses another formulation inspired by your comments. The updated document can be found here.
Regarding the linear relaxation from Section 5. The LP relaxation of the knapsack problem yields a solution where items can be split and are taken greedily by decreasing profit density (i.e. v_i/w_i) until the capacity is fully exhausted. The the implication of this relaxation are discussed extensively in the knapsack problem literature, but my experience is that many real-world knapsack instances have a structure which is well approximated by this relaxation. In this context the relaxation maybe even less of an issue because it will only effect the samples that exceed the capacity.
Concerning the number of samples. I am not an expert in statistics, so a theoretical bound is outside my expertise. However, if we had some “reasonable” input values for an instance of the problem we could conduct a numerical study that investigates how the input variance values and number of samples needed for solution convergence are related.
Sorry for the broken link. Guests cannot preview or edit their posts. A working link can be found here.