I’m excited to report that my first contribution back to the PyMC codebase was accepted. 🙂
It is a slight reworking of the pymc.Matplot.plot function that make it include autocorrelation plots of the trace, as well as histograms and timeseries. I also made the histogram look nicer (in my humble opinion).
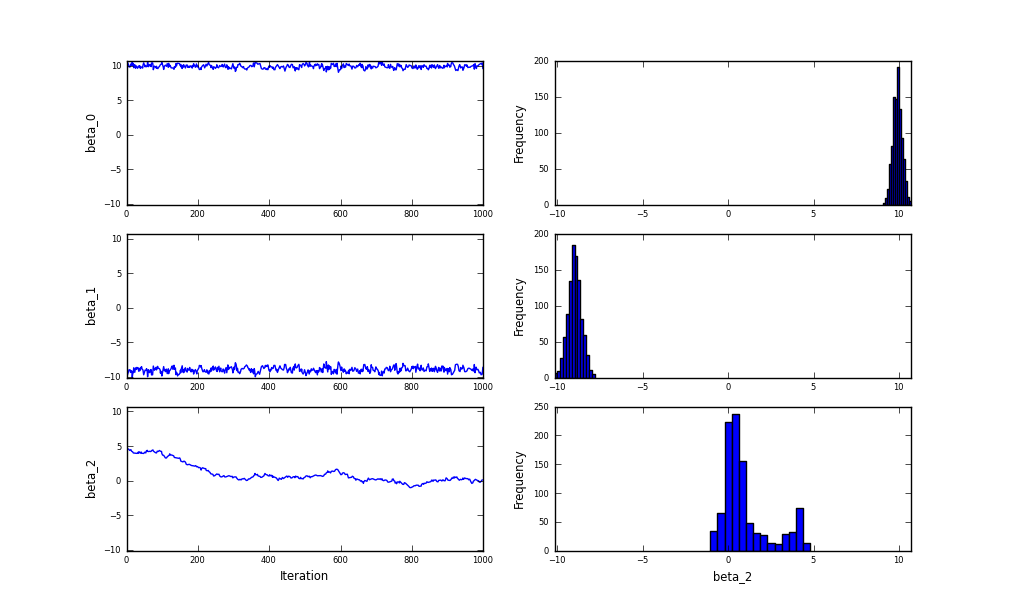
Before:

After:

In this example, I can tell that MCMC hasn’t converged from the trace of beta_2 without my changes, but it is dead obvious from the autocorrelation plot of beta_2 in the new version.
The process of making changes to the pymc sourcecode is something that has intimidated me for a while. Here are the steps in my workflow, in case it helps you get started doing this, too.
# first fork a copy of pymc from https://github.com/pymc-devs/pymc.git on github
git clone https://github.com/pymc-devs/pymc.git
# then use virtualenv to install it and make sure the tests work
virtualenv env_pymc_dev
source env_pymc_dev/bin/activate
# then you can install pymc without being root
cd pymc
python setup.py install
# so you can make changes to it without breaking everything else
# to test that it is working
cd ..
python
>>> import pymc
>>> pymc.test()
# then make changes to pymc...
# to test changes, and make sure that all of the tests that use to pass still do repeat the process above
cd pymc
python setup.py install
cd ..
python
>>> import pymc
>>> pymc.test()
# once everything is perfect, push it to a public git repo and send a "pull request" to the pymc developers.
Is there an easier way? Let me know in the comments.