
 I’m updating my CV, and that reminded me that I meant to promote this cool clustering technique that I was a little bit involved in, Clustering With Shallow Trees.
I’m updating my CV, and that reminded me that I meant to promote this cool clustering technique that I was a little bit involved in, Clustering With Shallow Trees.
This goes way back to about half-way through my post-doc at MSR, when statistical physicist Riccardo Zecchina was visiting for a semester, and was teaching me about all of the “intractable” optimization problems that he can solve using his panoply of propagation algorithms. In particular, he was working on algorithms for certain types of steiner tree optimization, and he had discovered that adding an extra constraint on the depth of the tree didn’t make the problem harder. (All variants of the problem he considers are NP-hard, but some are NP-harder than others.)
On the bus to work the next day, this depth constraint clicked with some complaints I had heard recently about the failures of single-linkage clustering in practice, that the algorithm produces long, stringy clusters, which are very sensitive to noise. Could having a knob to tune the depth of the spanning tree could be a way to address this? Riccardo worked hard on it for a long time, and brought a bunch of collaborators into the mix, and eventually they figured out how to make it work really well. They also proved that this approach interpolates between single-linkage (when the depth is unbounded) and the popular new affinity propagation technique (when the depth bound is 2.
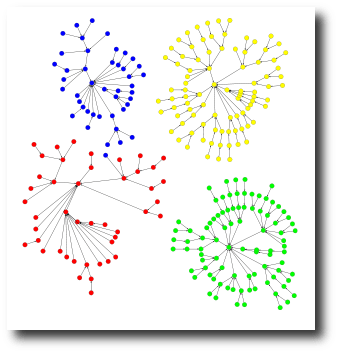
It turns out that something between SL and AP is the thing to do in many instances. Here is the home-run example from the paper, clustering people based on their SNPs:

Compare with the results of single linkage and affinity prop:

(What use is clustering people based on their genetic information? It’s important and scary to think about that…)
I got them to try applying it to a public health dataset as well, and the results are promising, but it needs more careful attention to be useful.
That reminds me: Riccardo and Team Survey Propagation, is the code for this available? We need to let other researchers try it on their own data if we want to give the technique a chance to take off.

Whoops, I spend all that time writing and forgot that the point was to figure out where we submitted the article, for inclusion in my CV. The Journal of Statistical Mechanics: Theory and Experiment.
Do you know any correspondence of this with embedding (multi commodity) flows? It seems like you are trying to embed flows with a bound on the dilation.
Ali: I don’t know of a correspondence, but I’d be happy to learning about one. Can you elaborate? What would the sources and sinks be?
At each node there will be a source for every other node and a corresponding sinks with a unit demand. Then this looks like what you might get when you impose a constraint on the maximum flow length while minimizing congestion.