
I’ve been reading up on probabilistic programming, it is so close to PyMC, but so different. Coolest example so far comes from a talk on Microsoft’s offering, infer.net:

I’ve been reading up on probabilistic programming, it is so close to PyMC, but so different. Coolest example so far comes from a talk on Microsoft’s offering, infer.net:
Comments Off on Probabilistic Programming Examples
Filed under probability, software engineering
I’ve had a secret project running in the background this week two weeks ago (how time flies!), a continuation of my work on bias reduction for traceroute sampling. It would be nice if this had applications to global health, but unfortunately (and uncharacteristically) I can’t think of any. It is a great opportunity for visualizing networks, though, a topic worthy of a quick post.
The bowl-of-spaghetti network visualization has been a staple of complex networks research for the last decade. I’m not convinced that there is anything interesting to learn from real world networks by drawing them in 2 or 3 dimensions, but the graphics a seriously eye catching. And I’m not convinced that there isn’t anything to learn from them, either. I invite you to convince me in the comments.

Interesting?
There are a lot of nice tools for doing this now, and just collecting the things I should consider in one place makes this post worthwhile for me. I learn towards a Pythonic solution of networkx driving graphviz, but there are some javascript options out there now that seem promising (jit, protovis, possibly more from a stackoverflow question) in. And for those looking for a less command-line-based solution, the Pajek system seems like a good route.
As for what to graph, here are my thoughts. The Erdos-Renyi graph doesn’t look good, and the Preferential Attachment graph doesn’t look good. Use them for your theorems and for your simulations, but when it comes time to draw something, consider a random geometric graph. And since these can be a little dense, you might want an “edge-percolated random geometric graph”.
I did have a little trouble with this approach, too, when I was drawing minimum spanning trees, because the random geometric points end up being placed really close together occasionally. So maybe the absolutely best random graph for illustrations would be a geometric graph with vertices from a “hard core” model, which is to say random conditioned on being a minimum distance apart. Unfortunately, it is an open question how to efficiently generate hard-core points. But it’s not hard to fake:

More informative?
Comments Off on Beautiful Networks
Filed under probability
As you have undoubtedly heard by now, there is a paper that claims to prove P!=NP, and there is a serious effort to understand the proof.
It has been fun to watch the experts set to work on this, and it has brought a lot of attention to random k-SAT, a problem that was near and dear to me when I was a grad student. And I get to learn interesting things from them without having to struggle through Deolalikar’s opus myself.
One interesting thing is the way Scott Aaronson reacted, saying:
If Vinay Deolalikar is awarded the $1,000,000 Clay Millennium Prize for his proof of P≠NP, then I, Scott Aaronson, will personally supplement his prize by the amount of $200,000.
When I first read about Aaronson’s offer to add $200K to the prize money, reported 2nd hand in a roundup of what the #pnp blogs were saying, it came off like the young professor is really hoping to have people work on this thing. But once my trusty rss feeder fed me his post, I realized his offer is not about how profs at private universities have disposable income that public schools don’t provide. It’s his way of quantifing his confidence in the accuracy of the proof.
If Aaronson had framed this in terms of a bet, it would be a textbook example of his level of certainty that the proof will have a flaw (a textbook in decision theory, anyway). But offering the sum without any possibility of receiving a return in the alternative scenario breaks expected utility theory. How certain is Scott? It all depends on what amount of money means nothing to him.
Filed under probability, TCS
James Lee has a new post on his tcsmath blog about Gaussian Processes, a topic I’ve been enamored with for the last while. I love the graphics he includes in his posts… they look like they take a lot of work to produce.
James (and Talagrand) are interested in finding the supremum of a GP, which I can imagine being a very useful tool for studying random graphs and average-case analysis of algorithms. I’m interested in finding rapidly mixing Markov chains over GPs, which seems to be useful for disease modeling. Seemingly very different directions of research, but I’ll be watching tcsmath for the next installment of majorizing measures.
Filed under probability
To take my mind off my meetings, I spent a little time modifying the Spatial Preferred Attachment model from Aiello, Bonato, Cooper, Janssen, and Prałat’s paper A Spatial Web Graph Model with Local Influence Regions so that it changes over time. Continue reading
Filed under combinatorics, probability
I’ve posted a new paper on random k-SAT on the arxiv. This is work I did towards the end of my post-doctoral stint at Microsoft Reseach with Danny Vilenchik and Uri Feige. It is an application of a cool technique that Danny and others came up with to study random instances above the satisfiability threshold that have been selected uniformly at random from satisfiable instances at that density. We use it to derive some bounds on the likely diameter of the set of satisfying solutions under this conditionally random distribution. Unfortunately, I don’t think that there are too many global health applications for random k-SAT with k large.
That’s too bad, because Amin Coja-Oghlan has also recently posted a paper about k-SAT on the arxiv, which sounds very promising. In A better algorithm for random k-SAT, Amin presents (from the abstract):
a polynomial time algorithm that finds a satisfying assignment of F with high probability for constraint densities
, where
. Previously no efficient algorithm was known to find solutions with non-vanishing probability beyond
.
His algorithm is a combinatorial, local-search type algorithm. I’ll try to find time to read the paper even if I don’t come up with a compelling application of k-SAT to health metrics.
Filed under probability, TCS
It’s been snowing in Seattle for a week now, and that never happens. Things were already getting quiet around here for the holidays, but now there are almost no cars on the roads and it’s been really quiet. I’ve been watching healthy algorithm videos to pass the nice, quiet time:

Gaussian Process Basics |

GP Covariance Functions |

Unnatural Causes |

The Trap |
Comments Off on Holiday Viewing
Filed under global health, probability, videos
I’ve got an urge to write another introductory tutorial for the Python MCMC package PyMC. This time, I say enough to the comfortable realm of Markov Chains for their own sake. In this tutorial, I’ll test the waters of Bayesian probability.

Tom Bayes
Now, what better problem to stick my toe in than the one that inspired Reverend Thomas in the first place? Let’s talk about sex ratio. This is also convenient, because I can crib from Bayesian Data Analysis, that book Rif recommended me a month ago.
Bayes started this enterprise off with a question that has inspired many an evolutionary biologist: are girl children as likely as boy children? Or are they more likely or less likely? Laplace wondered this also, and in his time and place (from 1745 to 1770 in Paris) there were birth records of 241,945 girls and 251,527 boys. In the USA in 2005, the vital registration system recorded 2,118,982 male and 2,019,367 female live births [1]. I’ll set up a Bayesian model of this, and ask PyMC if the sex ratio could really be 1.0.
Filed under MCMC, probability
A lovely stats paper appeared on the arxiv recently. Learning to rank with combinatorial Hodge theory, by Jiang, Lim, Yao, and Ye.
I admit it, the title is more than a little scary. But it may be the case that no more readable paper has so intimidating a title, and no more intimidatingly titled a paper is more readable.
Comments Off on Learning to Rank
Filed under combinatorial optimization, probability
This post is a little tutorial on how to use PyMC to sample points uniformly at random from a convex body. This computational challenge says: if you have a magic box which will tell you yes/no when you ask, “Is this point (in n-dimensions) in the convex set S”, can you come up with a random point which is nearly uniformly distributed over S?
MCMC has been the main approach to solving this problem, and it has been a great success for the polynomial-time dogma, starting with the work of Dyer, Frieze, and Kannan which established the running-time upper bound of 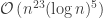
Filed under MCMC, probability
