
A lovely stats paper appeared on the arxiv recently. Learning to rank with combinatorial Hodge theory, by Jiang, Lim, Yao, and Ye.
I admit it, the title is more than a little scary. But it may be the case that no more readable paper has so intimidating a title, and no more intimidatingly titled a paper is more readable.
The rank aggregation problem has been big in TCS research in the last few years, driven largely by the observation that different search engines take the same query and order the results differently. If there was only some way to combine their orderings into the perfect ordering, wouldn’t that be worth even more billions than Google alone? (Probably not…) However, it does lead to some interesting algorithmic challenges, and one of the best named is “Minimum Feedback Arc Set on Tournaments”. In addition to being a nice special case of the classic “Minimum Feedback Arc Set” problem, it is also a classic problem in the theory of social choice, the Kemeny-Young voting method. It also is a lot like sorting lists, which is one of the places that average-case analysis of algorithms has been most triumphant. (Does anyone have a nice bibliography on this?)
One thing that I love about the Hodge Theory paper is that the authors are really clear about what their approach offers. In their words:
Our objective towards rank-learning is two-fold: like everybody else, we want to deduce a global ranking from the data whenever possible; but in addition to that, we also want to detect when the data does not permit a statistically meaningful global ranking and in which case characterize the data in terms of its local and global inconsistencies
The basic idea is this: Given relative information about alternatives (in the form of a matrix X, with 

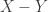
I didn’t start reading a paper with this title just to punish myself. We are trying to make lists all the time in health metrics, so rank aggregation comes up not infrequently. And I’m not in that fairytale theoryland anymore… there is noise in my pairwise comparison values, and I have confidence intervals on the noise, and I need an ordering that reflects that uncertainty as well. Do this sound too abstract? I’ll describe in more detail one application area that might actually happen this spring.
The Global Burden of Disease (GBD) study is a massive study to quantify the burden caused to the world by over a hundred diseases and injuries. The World Health Organization has a lot more to say about it if you really want to dig in [1].
The way GBD quantifies the burden of any particular disease is in Disability Adjusted Life Years (or DALYs), which is an attempt to say how many person-years the disease has removed from the world. This is a pretty complicated quantity to measure, when you start thinking about it, and the WHO has a sketch of how it is calculated [2].
A very important piece of calculating DALYs are the disability weights. This is the coefficient which indicates how severe the symptoms of a disease are (if 1.0 = full health and 0.0 = dead, how should we weight common cold symptoms?) It turns out that people aren’t so good at assigning absolute numbers, but maybe they are better at answering would-you-rather questions.
So suppose that we do surveys or whatever, and we get answers to many of these would-you-rather questions. Then we need to get disability weights out of the answers. Maybe combinatorial Hodge Theory is the way to do it.
