
I’ve got an urge to write another introductory tutorial for the Python MCMC package PyMC. This time, I say enough to the comfortable realm of Markov Chains for their own sake. In this tutorial, I’ll test the waters of Bayesian probability.

Tom Bayes
Now, what better problem to stick my toe in than the one that inspired Reverend Thomas in the first place? Let’s talk about sex ratio. This is also convenient, because I can crib from Bayesian Data Analysis, that book Rif recommended me a month ago.
Bayes started this enterprise off with a question that has inspired many an evolutionary biologist: are girl children as likely as boy children? Or are they more likely or less likely? Laplace wondered this also, and in his time and place (from 1745 to 1770 in Paris) there were birth records of 241,945 girls and 251,527 boys. In the USA in 2005, the vital registration system recorded 2,118,982 male and 2,019,367 female live births [1]. I’ll set up a Bayesian model of this, and ask PyMC if the sex ratio could really be 1.0.
The simple model of the situation is that there is some number ![p_b \in [0,1]](https://s0.wp.com/latex.php?latex=p_b+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
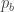

Mathematically, if 
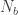
![\Pr[N_b = k | p_b = p, N = n] = \binom{n}{k} p^k(1-p)^{n-k}](https://s0.wp.com/latex.php?latex=%5CPr%5BN_b+%3D+k+%7C+p_b+%3D+p%2C+N+%3D+n%5D+%3D+%5Cbinom%7Bn%7D%7Bk%7D+p%5Ek%281-p%29%5E%7Bn-k%7D&bg=ffffff&fg=333333&s=0&c=20201002)
You can think of this as a one parameter model. If I tell the model 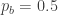
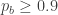

In PyMC, it’s 4 lines to set up this model:
from pymc import *
p_b = Uniform('p_b', 0.0, 1.0)
N_b = Binomial('N_b', n=4138349, p=p_b, value=2118982, observed=True)
m = Model([p_b, N_b])
To see the posterior log-probability for a particular value of
p_b.value = 0.5 print m.logp
Here is the plot:

First Bayesian Example
This simple example is so simple that you don’t need any MCMC. But it would be easy to do some if you did.
mc = MCMC(m) mc.sample(iter=50000,burn=10000) hist(p_b.trace())

To return to the thought that I’ve been holding, I know that 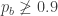
p_b using something like p_b = Uniform('p_b', 0.0, 0.95), but I’d also be surprised to learn that 
p_b = Normal('p_b', 0.5, 0.2) is a good way to go. I don’t know what the pros would think of that; they seem to favor an exotic prior, like p_b = Beta('p_b', 10, 10) which is “conjugate” in this case.
To turn the problem around (and put it in a context I’m familiar with from work), how concentrated does the prior have to be to model a doctor who believes that
For bonus points, with PyMC we can go beyond the work of Bayes, and model the uncertainty in the vital registration system. These numbers for the USA are probably very close to perfect. But I would be more skeptical of the accuracy for the 241,945 girls and 251,527 boys recorded during Laplace’s day. And how can I represent my skepticism? Maybe I’ll represent it as a normally distributed error with standard deviation 10000.
from pymc import *
p_b = Uniform('p_b', 0.0, 1.0)
e_N = Normal('e_N', 0.0, 1.0/(10000.0)**2)
e_N_b = Normal('e_N_b', 0.0, 1.0/(10000.0)**2)
@potential
def likelihood(N_b=251527, e_N_b=e_N_b, N=241945+251527, e_N=e_N, p=p_b):
return binomial_like(N_b + e_N_b, N + e_N, p)
mc = MCMC([p_b, N, N_b, likelihood])
Easy, right? Well, easy to write. Can you get PyMC to draw believable samples from it? I can, but it takes a little longer. Remember to thin your samples!

How did you make the plot of the posterior log-probability? Is there a function in PyMC to do that, or did you just plot the distribution by writing a separate function?
Erik: There is not a PyMC function to make that plot, and it took me a line or two more Python than it should, so I didn’t include it in the example. Here is what it takes to get started:
p_vals = arange(0.01,1.0,.01) logpr_vals = [] for p in p_vals: p_b.value = p logpr_vals.append(m.logp) plot(p_vals, logpr_vals)To get a zoomed-in view of the piece where the action is, use
p_vals = arange(0.51,0.515,0.00001)as line 1. Then it will even look nice withplot(p_vals,exp(array(logpr_vals))).I found the cool way to make that plot.
🙂
> so maybe something like p_b = Normal(‘p_b’, 0.5, 0.2) is a good way
> to go
The problem with allowing the parameter p_b to be distributed Normally
is that a Normal distribution would assign positive probability to
p_b>1.0 and p_b<0. Though you can make this probability vanishingly
small by choosing an appropritately small variance, it will always be
positive. This is why more "exotic" distributions are prefered for
distributions over parameters than have a constrained range.
@Josh, there is also the
Truncnormstoch in PyMC, which combines the familiarity of the normal distribution with the appropriate support of the beta distribution. Here is some PyMC documentation on it, together with an example of a custom step method that doesn’t waste time stepping over the edge: example-an-asymmetric-metropolis-step.Pingback: 2010 in review | Healthy Algorithms
Thank you, that was a useful post. Going to use this tutorial for a completely different project.
Great, if there is something to show from your project please post a link here, I’d love to see how this lives on.