
PyMC2 has some tricky tricks for reducing function evaluations if possible. A question asked and answered on Stack Overflow investigates: http://stackoverflow.com/q/27714635/1935494 and I made a IPython Notebook with more details, too: http://nbviewer.ipython.org/gist/aflaxman/c07c5261bf22f6847098
Tag Archives: pymc
A little PyMC2 trick
Here is a little trick for getting around a pesky initialization issue in PyMC2 models, asked and answers on Stack Overflow when thing were quiet around here: http://stackoverflow.com/a/27724637/1935494
Comments Off on A little PyMC2 trick
Filed under software engineering
PyMC3 with PyMC2
Did you know I have a fork of PyMC3 that you can run at the same time as PyMC2? I don’t keep it up to date, but people seem to want it every once in a while. Maybe this will help someone find it: https://github.com/aflaxman/pymc
import pymc as pm2 import pymc3 as pm3
Good for head-to-head comparisons…
Comments Off on PyMC3 with PyMC2
Filed under software engineering
Bayesian Correlation in PyMC
Here is a StackOverflow question with a nice figure:

Is there a nice, simple reference for just what exactly these graphical model figures mean? I want more of them.
Filed under statistics
MCMC in Python: observed data for a sum of random variables in PyMC
I like answering PyMC questions on Stack Overflow, but sometimes I give an answer and end up the one with the question. Like what would you model as the sum of a Poisson and a Negative Binomial?
Comments Off on MCMC in Python: observed data for a sum of random variables in PyMC
Filed under statistics
MCMC in Python: sim and fit with same model
Here is a github issue and solution that I saw the other day. I think it’s a nice pattern.
def generate_model(values={'mu': true_param, 'm': None}):
#prior
mu = pymc.Uniform("mu", lower=-10, upper=10, value=values['mu'],
observed=(values['mu'] is not None))
# likelihood function
m = pymc.Normal("m", mu=mu, tau=tau, value=values['m'],
observed=(values['m'] is not None))
return locals()
Comments Off on MCMC in Python: sim and fit with same model
Filed under statistics
MCMC in Python: Fit a non-linear function with PyMC
Here is a recent q&a on stack overflow that I did and liked.
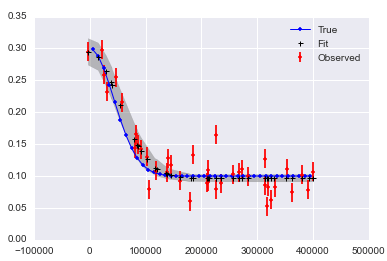
Comments Off on MCMC in Python: Fit a non-linear function with PyMC
Filed under statistics
MCMC in Python: a bake-off
While I’m on a microblogging spree, I’ve been meaning to link to this informative comparison of pymc, emcee, and pystan: http://jakevdp.github.io/blog/2014/06/14/frequentism-and-bayesianism-4-bayesian-in-python/
Comments Off on MCMC in Python: a bake-off
Filed under statistics
MCMC in Python: Another thing that turns out to be hard
Here is an interesting StackOverflow question, about a model for data distributed as the sum of two uniforms with unknown support. I was surprised how hard it was for me.
I think the future of probabilistic programming should be to make a model for this easy to code.
Comments Off on MCMC in Python: Another thing that turns out to be hard
Filed under statistics
MCMC in Python: Never… no… always check for convergence
I’ve had no teaching responsibilities over the last quarter, and I must miss it. I’ve found myself responding to PyMC questions on StackOverflow more than ever before. It is an interesting window into what is hard in Bayesian computation. Checking (and achieving) MCMC convergence is one thing that is hard. Here are some questions and answers that include it:
http://stackoverflow.com/questions/24294203/difference-between-bugs-model-and-pymc/24347102#24347102
http://stackoverflow.com/questions/24242660/pymc3-multiple-observed-values/24271760#24271760
http://stackoverflow.com/questions/24402834/fitting-power-law-function-with-pymc/24413323#24413323
Comments Off on MCMC in Python: Never… no… always check for convergence
Filed under statistics
