
A multitude of events in the last week or so have made me want to blog about (and learn more about) the cryptographic theory of privacy. Journalist James Bamford’s new book about the NSA came out, the third in his trilogy. Bamford described his findings on Democracy Now last Tuesday, including how government contractors were hired to eavesdrop on US soldiers in Iraq:
Not only were they eavesdropping on a lot of these conversations, some of which were very intimate, but they would have sort of locker room chats about what they were hearing, and they would post—or they would notify their co-workers that you should listen to this, what they call “cut,” their conversations. You should listen to this conversation or that conversation. They’d laugh about it.
Also last week, (or maybe two weeks ago) the National Academy Press published a new report called Protecting Individual Privacy in the Struggle Against Terrorists. The report’s primary recommendation, that “Programs Should be Evaluated for Effectiveness, Privacy”, is not too revolutionary, but the report contains some interesting summaries of technology and public opinion.
And kicking off this season of privacy discussion, there were demonstrations across the EU on Oct 11 in a world-wide protest against surveillance entitled Freedom not fear.
Or, almost kicking it off… just a few weeks before this tsunami of privacy, Adam Smith posted an interesting sounding paper to the arxiv, Efficient, Differentially Private Point Estimators. This sort of cryptographic approach to privacy is where I’m going with this post. But let me first mention why I’m going there.
In general, surveillance is something that people have strong feelings about, and this has been the case for a long time. The US Bill of Rights, for example, addresses it explicitly in the 4th Amendment:
The right of the people to be secure in their persons, houses, papers, and effects, against unreasonable searches and seizures, shall not be violated, and no Warrants shall issue, but upon probable cause, supported by Oath or affirmation, and particularly describing the place to be searched, and the persons or things to be seized.
And personal health records are a place where people really care about their privacy. The National Academy report summarizes some relevant public opinion polls:
(p. 306) In 2000, Gallop asked respondents, “Would you support a plan that requires every American, including you, to be assigned a medical identification number, similar to a social security number, to track your medical records and place them in a national computer database without your permission?”
Anyone want to guess the response? 91% of respondents opposed the plan. But that’s no way to ask! Here’s a more positive approach
(p. 309) In 2003, Parade Magazine asked respondents whether, “assuming that there was no way that anyone will have access to your identity,” they would be willing to release health information for various purposes. 67% said they would share health information in order for “researchers to learn about the quality of health care, disease treatment, and prevention, and other related issues.”
In just two month of hanging around IHME, it’s become totally clear that individual health information is incredibly valuable in global health decision making. And, according to these survey results, collecting this information is much more palatable to folks assuming it cannot be linked back to individuals. Is that a lot to assume? In TCS, there is a line of research in differential privacy which attempts to answer this question.
Differential Privacy draws on the foundations of cryptography, and so, like all cryptography research, it is completely obsessed with definitions (and a little paranoid). What is privacy? Cynthia Dwork, the Microsoft researcher who has been in the forefront of this crypto approach, says that individual privacy is when the individual blends in with the crowd. But making that into a formal definition is a challenge. Consider a medical database 

An attempt to formalize database privacy, by Tore Dalenius in the 70s, proposed that, in a privacy-preserving database, anything which could be inferred about an individual from the database could also be inferred without the database. Cynthia showed that this goal is unattainable; there is no way a useful database can be this private (you might wonder what the definition of useful is… it’s in the paper). An alternative definition, championed by Cynthia, is differential privacy. Formally, we consider a randomized function which operates on a database. In the example above (the one with your data in it), a very important function is the fraction of the population which is HIV-positive. Let’s call this function 

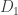
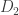
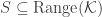
![\Pr[\mathcal K(D_1) \in S] \leq \exp(\epsilon)\times \Pr[\mathcal K(D_2) \in S]](https://s0.wp.com/latex.php?latex=%5CPr%5B%5Cmathcal+K%28D_1%29+%5Cin+S%5D+%5Cleq+%5Cexp%28%5Cepsilon%29%5Ctimes+%5CPr%5B%5Cmathcal+K%28D_2%29+%5Cin+S%5D&bg=ffffff&fg=333333&s=0&c=20201002)
There are a few nice things about this definition. It says something pretty strong about the privacy of an individual: if a single row is changed in any way, then the probability of any outcome changes by at most 
This is the point where the area starts to escape from my grasp. With or without this definition, I think that the only game in town is adding noise. Steve Fienberg has a number of papers, which provide some insight into how statisticians approach this issue. His general formulation is to say view the database 

So, perhaps having piqued your interest, I’ll stop here, with an example slide from a talk by Adam Smith.

Here are some parting shots, which I forgot to integrate into the flow above.
A claim from Protecting Individual Privacy that would making Machiavelli proud:
(p. 284) However, most people are tolerant of surveillance when it is aimed at specific racial or ethnic groups, when it concerns activities they do not engage in, or when they are not focusing on its potential personal impact. We note that people are not concerned about privacy in general, but rather with protecting the privacy of information about themselves.
(Is this supported in the chapter? I didn’t see how, but I was skimming.)
Latanya Sweeny gave this area a huge boost by showing that commercially available “de-identified” health information could be re-identified to recover the medical records of then Massachusettes governor Bill Weld.
And last but not least, WordPress has just added polls! Here’s a relevant poll:

Pingback: Google Flu « Healthy Algorithms
Pingback: Big opportunity for differential privacy « Healthy Algorithms