In the classic paper on the EM algorithm, the extensive example section begins with a multinomial modeling example that is theoretically very similar to the warm-up problem on 197 animals:
We can think of the complete data as an 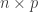 matrix
matrix  whose
whose  element is unity if the
element is unity if the  -th unit belongs in the
-th unit belongs in the  -th of
-th of  possible cells, and is zero otherwise. The -th row of contains
possible cells, and is zero otherwise. The -th row of contains 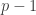 zeros and one unity, but if the -th unit has incomplete data, some of the indicators in the -th row of are observed to be zero, while the others are missing and we know only that one of them must be unity. The E-step then assigns to the missing indicators fractions that sum to unity within each unit, the assigned values being expectations given the current estimate of
zeros and one unity, but if the -th unit has incomplete data, some of the indicators in the -th row of are observed to be zero, while the others are missing and we know only that one of them must be unity. The E-step then assigns to the missing indicators fractions that sum to unity within each unit, the assigned values being expectations given the current estimate of  . The M-step then becomes the usual estimation of from the observed and assigned values of the indicators summed over the units.
. The M-step then becomes the usual estimation of from the observed and assigned values of the indicators summed over the units.
In practice, it is convenient to collect together those units with the same pattern of missing indicators, since the filled in fractional counts will be the same for each; hence one may think of the procedure as filling in estimated counts for each of the missing cells within each group of units having the same pattern of missing data.
When I first made some data to try this out, it looked like this:
import pymc as mc, numpy as np, pandas as pd, random
n = 100000
p = 5
pi_true = mc.rdirichlet(np.ones(p))
pi_true = np.hstack([pi_true, 1-pi_true.sum()])
x_true = mc.rmultinomial(1, pi_true, size=n)
x_obs = array(x_true, dtype=float)
for i in range(n):
for j in random.sample(range(p), 3):
x_obs[i,j] = np.nan
At first, I was pretty pleased with myself when I managed to make a PyMC model and an E-step and M-step that converged to something like the true value of  . The model is not super slick:
. The model is not super slick:
pi = mc.Uninformative('pi', value=np.ones(p)/p)
x_missing = np.isnan(x_obs)
x_initial = x_obs.copy()
x_initial[x_missing] = 0.
for i in range(n):
if x_initial[i].sum() == 0:
j = np.where(x_missing[i])[0][0]
x_initial[i,j] = 1.
@mc.stochastic
def x(pi=pi, value=x_initial):
return mc.multinomial_like(value, 1, pi)
@mc.observed
def y(x=x, value=x_obs):
if np.allclose(x[~x_missing], value[~x_missing]):
return 0
else:
return -np.inf
And the E-step/M-step parts are pretty simple:
def E_step():
x_new = array(x_obs, dtype=float)
for i in range(n):
if x_new[i, ~x_missing[i]].sum() == 0:
conditional_pi_sum = pi.value[x_missing[i]].sum()
for j in np.where(x_missing[i])[0]:
x_new[i,j] = pi.value[j] / conditional_pi_sum
else:
x_new[i, x_missing[i]] = 0.
x.value = x_new
def M_step():
counts = x.value.sum(axis=0)
pi.value = (counts / counts.sum())
But the way the values converge does look nice:

The thing that made me feel silly was comparing this fancy-pants approach to the result of averaging all of the non-empty cells of x_obs:
ests = pd.DataFrame(dict(pr=pi_true, true=x_true.mean(0),
naive=pd.DataFrame(x_obs).mean(), em=pi.value),
columns=['pr', 'true', 'naive', 'em']).sort('true')
print np.round_(ests, 3)
pr true naive em
2 0.101 0.101 0.100 0.101
0 0.106 0.106 0.108 0.108
3 0.211 0.208 0.209 0.208
1 0.269 0.271 0.272 0.271
4 0.313 0.313 0.314 0.313
Simple averages are just as good as EM, for the simplest distribution I could think of based on the example, anyways.
To see why this EM business is worth the effort requires a more elaborate model of missingness. I made one, but it is a little bit messy. Can you make one that is nice and neat?