
This week in journal club we are discussing Rudan et al, Epidemiology and etiology of childhood pneumonia in 2010. This description of an estimation method comes with an 80 page spreadsheet showing the calculation!
Monthly Archives: October 2013
Journal Club: Epidemiology and etiology of childhood pneumonia in 2010
Comments Off on Journal Club: Epidemiology and etiology of childhood pneumonia in 2010
Filed under disease modeling, global health
Mortality in Iraq paper out
I was traveling last week for a verbal autopsy conference, and now that I’m catching up I can share this: my study on Mortality in Iraq Associated with the 2003–2011 War and Occupation has been published in PLoS Medicine.
It is great that this paper got some media coverage, because it was really hard work. Here are a few examples of how the science looked in the popular press:
http://www.latimes.com/world/la-fg-iraq-war-deaths-20131016,0,6128082.story
http://news.nationalgeographic.com/news/2013/10/131015-iraq-war-deaths-survey-2013/
Lots of moving photos in the files to accompany this story!
Comments Off on Mortality in Iraq paper out
Filed under global health
IHME Seminar: Ziad Obermeyer on Improving Prognosis
This week we heard from Ziad Obermeyer, a former IHMEer, and current Harvard prof and ER doc, about using big data to understand costs and improve predictions in the health system. And he didn’t say “big data” the whole time. Perhaps the video will appear here.
Comments Off on IHME Seminar: Ziad Obermeyer on Improving Prognosis
Filed under global health, machine learning
IHME Seminar: Emily Fox on Bayesian Dynamic Modeling
This week we had a seminar on Bayesian Dynamic Modeling from UW Stats professor Emily Fox. The video is archived here! This talk had some of the most successful embedded video that I’ve seen in a talk. I don’t think it made it into the video perfectly, though, so imagine dancing honeybees while you watch.
Comments Off on IHME Seminar: Emily Fox on Bayesian Dynamic Modeling
Filed under machine learning, statistics
Journal Club: Assessment of statistical models
This week in journal club, we will be reading Green et al, Use of posterior predictive assessments to evaluate model fit in multilevel logistic regression. I like posterior predictive checks, here are some of the stats papers that we might read in the future if my students do, too:
Click to access GelmanMengStern1996.pdf
http://onlinelibrary.wiley.com/doi/10.1002/1097-0258(20000915/30)19:17/18%3C2377::AID-SIM576%3E3.0.CO;2-1/pdf
Comments Off on Journal Club: Assessment of statistical models
Filed under statistics
Where does the term “covariate” come from?
I’ve been hard at work revising my DisMod-MR book, and one thing that has been fun is recognizing the jargon that is so embedding my working language that I’ve never thought about it before. What is a “covariate”? It is any data column in my tabular array that is not the most important one. But how do I know that? This word is not actually English.
I asked where the term comes from on CrossValidated, and got a good answer, as well as a link to a whole website of earliest known uses of some of the words of mathematics.
The first use of this word in a JSTOR-archived article is in Proceedings of a Meeting of the Royal Statistical Society held on July 16th, 1946, and it captures all the basics of how I am using it today (although my setting is observational, not experimental):
A simple example occurs in crop-cutting experiments. In the Indian Statistical Institute the weight of green plants of jute or the weight of paddy immediately after harvesting are recorded on an extensive scale. In only a small fraction of cases (of the order of 10 %) the jute plant is steeped in water, retted and the dry fibre extracted and its weight determined directly, or the paddy is dried, husked and the weight of rice measured separately. These auxiliary measurements serve to supply the regression relation between the weight of green plants of jute or the weight of paddy immediately after harvesting and the yield of dry fibre of jute or of husked rice, respectively, which can then be used to estimate the corresponding final yields from the more extensive weights taken immediately after harvesting. Such a procedure simplifies the field work enormously without any appreciable loss of precision in the final results.
Such methods, in which the estimates made in later surveys are based on correlations determined in earlier surveys, may perhaps be called “covariate sampling”.
Comments Off on Where does the term “covariate” come from?
Filed under statistics
Statistics in Python: Bootstrap resampling with numpy and, optionally, pandas
I’m almost ready to do all my writing in the IPython notebook. If only there was a drag-and-drop solution to move it into a wordpress blog. The next closest thing: An IPython Notebook on Github’s Gist, linked from here. This one is about bootstrap resampling with numpy and, optionally, pandas.
Comments Off on Statistics in Python: Bootstrap resampling with numpy and, optionally, pandas
Filed under statistics
IHME Seminar: Captricity
We had a live-streamed seminar at IHME this week! I’m very excited to hear that it worked. The talk was good, too.
We heard from Kuang Chen, the founder and CEO of Captricity (http://captricity.com/), about how this “beyond OCR” approach to data entry went from academic research to a Silicon Valley startup. To show off what they can do, Captricity has a number of cool datasets that they have transformed from unsearchable PDFs into well-groomed csv files. For example, the USA 1940 census: https://shreddr.captricity.com/opendata/1940-census/
I could see using this service in my future, maybe for a VA survey or something similar. But what really grabbed me was the datasets they are making available. Their data gallery a place I’ll be watching: https://shreddr.captricity.com/opendata/
Comments Off on IHME Seminar: Captricity
Filed under global health
Journal Club: Socioeconomic development as an intervention against malaria
The quarter is underway, and journal club is back. This week will will discuss Tusting et al’s meta-analysis of socioeconomic development as an intervention against malaria.
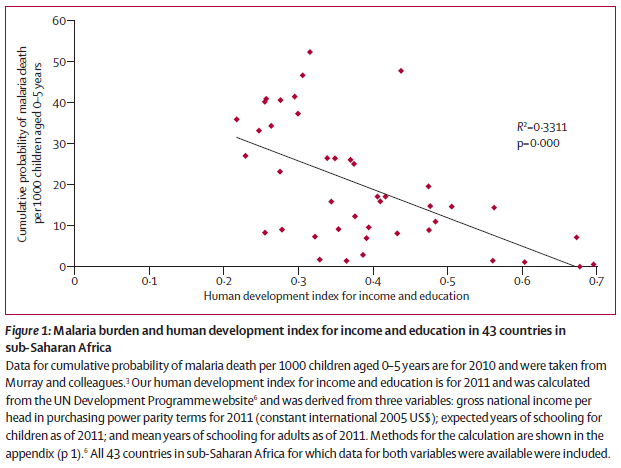
I wonder if the forest plot is here to stay?

It presents a lot of information, but maybe it could emphasize the important parts more. There is great benefit to having a standard way to present systematic review data, however, so any changes need to be for huge benefit or just little tweaks.
Comments Off on Journal Club: Socioeconomic development as an intervention against malaria
Filed under global health
