
This National Health Statistics Report that we read toward the end of last quarter’s journal club has one of the driest names we’ve seen. But the topic is a fascinating glimpse into the limits of our knowledge about society. How many households in USA have given up their landline phone entirely and only have a cell phone? Well, we answer most questions like that with a telephone survey. Uh-oh. Fortunately the National Health Interview Survey (in my experience, pronounced most commonly as “en-hiss”) is a health survey were enumerators visit households in person, and even though it is about population health, it can also answer this pressing question about technology use (and the potential invalidity of all of the surveys that do not visit households in person, but just call on the phone).
Category Archives: global health
Journal Club: Wireless Substitution: State-level Estimates From the National Health Interview Survey, January 2007–June 2010
Comments Off on Journal Club: Wireless Substitution: State-level Estimates From the National Health Interview Survey, January 2007–June 2010
Filed under global health
I used the IPython Notebook for my lab book for a year. How did it go?
It was exactly a year ago when I firmed up a workflow wherein the IPython Notebook was the center of my daily scientific research. All notes end up in a .ipynb file, and my code, plots, and equations all live together there. Looking back on 2013, how did it go and what should I change for 2014?
I am very happy with it overall. I have 641 .ipynb files, with names like 2013_01_01_EM_4_1_2.ipynb and 2013_12_22a_dm_pde_for_pop_prediction.ipynb. This includes notes for two courses I taught and plan to teach again, for several papers that we published, and for a large number of projects that didn’t pan out. I’ll definitely use the course notes again the next time I teach, I’ve already had to look up the calculations from some of those papers for responses to reviewers and clarifications after publication, and maybe I can come back to projects that didn’t pan out in the future with some new insight.
What could go better? I couldn’t decide if my lab book should capture everything, like I was taught in science class, or have a curated collection of my work including only the parts I would need in the future. Probably some blend is best, and since it is hard to know the right balance ahead of time, I tried to keep everything in a git repo, so that I could curate and edit, but recover anything that I realized I still wanted after cutting. I only ended up with 59 git commits, though. If that approach was working, I would expect more commits than notebooks.
I sometimes lost things in my stack of notebooks. The .ipynb format is not easy to search, so I kept a .py copy of everything and grepped through them looking for the notebooks about a specific technique or project. Since I organized my notebooks chronologically, I ended up doing this a lot more than if I had organized them thematically, but even if I already had all of my congenital heart disease notes in one place, I would still find myself saying, “I know I did some data munging like this for a different project recently, how does the pandas.melt function work again?”, or whatever.
The feature I would like the most is a way to paste images into my notebook. I wrote some notes about it in a github issue page about IPython Notebook feature requests. I want the digital equivalent of stapling a copy into my lab book, and I want it to be easy.
Collaboration worked pretty well. I have a lot of colleagues who don’t want to see Python code, no matter how much easier it would make their lives. I’ve had good success sending them pdf version of notebooks, or sticking my research notes in a github gist and sending them a link to nbviewer. I think there is room for improvement in this, too, though.
Filed under global health
IHME Seminar: Caleb Banta-Green on Drugs in Toilet Water
I’m catching up on all the happenings around IHME while I was busy last quarter, and here is the one where information technology served me the best. The Wednesday seminar from Oct 30 was a particularly cool approach to finding out about “hidden health behaviors” from waste water monitoring, like if there is more psychostimulant use in urban or rural settings.
It is the one where information technology served me the best because I was traveling when this seminar happened, and I watched it in a live broadcast online when I couldn’t fall asleep in Geneva. Yay technology. You can watch it now, too, in archived form. Yay, again.
Comments Off on IHME Seminar: Caleb Banta-Green on Drugs in Toilet Water
Filed under global health
The Age Pattern of Mortality: a challenge for our fancy new MCMC methods
I’ve come across this demographer’s classic a few times while learning about Global Health, The Age Pattern of Mortality by Heligman and Pollard. (Note this is J H Pollard, actuary, not to be confused with J M Pollard, cryptographer.)
This paper comes up with a very appealing parameterization of age-specific mortality, in a model that is highly nonlinear and turns out to be quite a pain for computation.

Appealing because the three terms in the sum have good demographic interpretations:
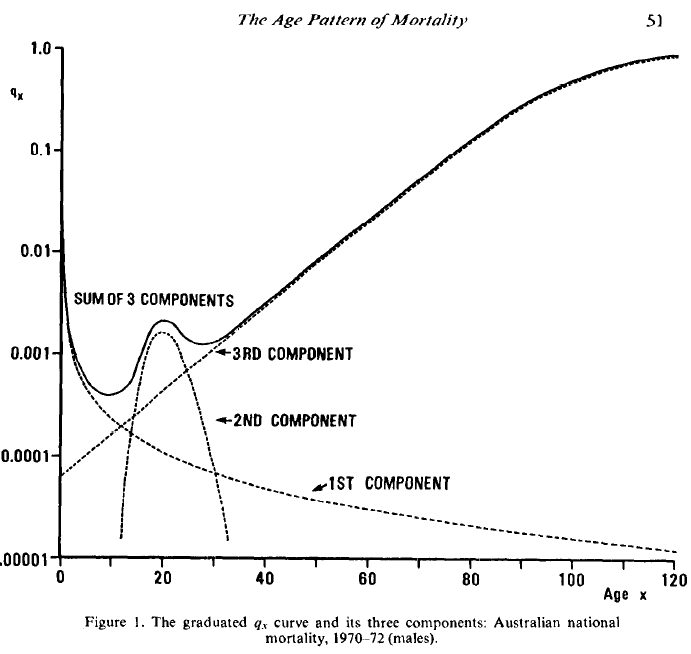
Quite a pain for computation because some of the parameters are very co-linear, or maybe co-non-linear, if that is a word:

It would be cool to see PyMC3 make short work of this, and I managed to code it up, but I haven’t been able to fit it yet. Patches welcome.
with pm.Model() as m:
a = pm.Flat('a')
b = pm.Flat('b')
c = pm.Flat('c')
d = pm.Flat('d')
e = pm.Flat('e')
f = pm.Flat('f')
g = pm.Flat('g')
h = pm.Flat('h')
t1 = a**((x+b)**c)
t2 = d * T.exp(-e * T.log(x/f)**2)
t3 = g*h**x
y_pred = t1 + t2 + t3
y_obs = pm.Normal('y_obs', mu=y_pred/y, sd=1.,
observed=ones_like(y))
Comments Off on The Age Pattern of Mortality: a challenge for our fancy new MCMC methods
Filed under global health
Journal Club: Parental income and health inequality
Continuing to catch up on my record of journal club topics, just under a month ago we read Parental income and the dynamics of health inequality in early childhood–evidence from the UK. There was a discussion of whether this was typical for a health economics paper.
Comments Off on Journal Club: Parental income and health inequality
Filed under global health
Journal Club: Epidemiology and etiology of childhood pneumonia in 2010
This week in journal club we are discussing Rudan et al, Epidemiology and etiology of childhood pneumonia in 2010. This description of an estimation method comes with an 80 page spreadsheet showing the calculation!
Comments Off on Journal Club: Epidemiology and etiology of childhood pneumonia in 2010
Filed under disease modeling, global health
Mortality in Iraq paper out
I was traveling last week for a verbal autopsy conference, and now that I’m catching up I can share this: my study on Mortality in Iraq Associated with the 2003–2011 War and Occupation has been published in PLoS Medicine.
It is great that this paper got some media coverage, because it was really hard work. Here are a few examples of how the science looked in the popular press:
http://www.latimes.com/world/la-fg-iraq-war-deaths-20131016,0,6128082.story
http://news.nationalgeographic.com/news/2013/10/131015-iraq-war-deaths-survey-2013/
Lots of moving photos in the files to accompany this story!
Comments Off on Mortality in Iraq paper out
Filed under global health
IHME Seminar: Ziad Obermeyer on Improving Prognosis
This week we heard from Ziad Obermeyer, a former IHMEer, and current Harvard prof and ER doc, about using big data to understand costs and improve predictions in the health system. And he didn’t say “big data” the whole time. Perhaps the video will appear here.
Comments Off on IHME Seminar: Ziad Obermeyer on Improving Prognosis
Filed under global health, machine learning
IHME Seminar: Captricity
We had a live-streamed seminar at IHME this week! I’m very excited to hear that it worked. The talk was good, too.
We heard from Kuang Chen, the founder and CEO of Captricity (http://captricity.com/), about how this “beyond OCR” approach to data entry went from academic research to a Silicon Valley startup. To show off what they can do, Captricity has a number of cool datasets that they have transformed from unsearchable PDFs into well-groomed csv files. For example, the USA 1940 census: https://shreddr.captricity.com/opendata/1940-census/
I could see using this service in my future, maybe for a VA survey or something similar. But what really grabbed me was the datasets they are making available. Their data gallery a place I’ll be watching: https://shreddr.captricity.com/opendata/
Comments Off on IHME Seminar: Captricity
Filed under global health
Journal Club: Socioeconomic development as an intervention against malaria
The quarter is underway, and journal club is back. This week will will discuss Tusting et al’s meta-analysis of socioeconomic development as an intervention against malaria.
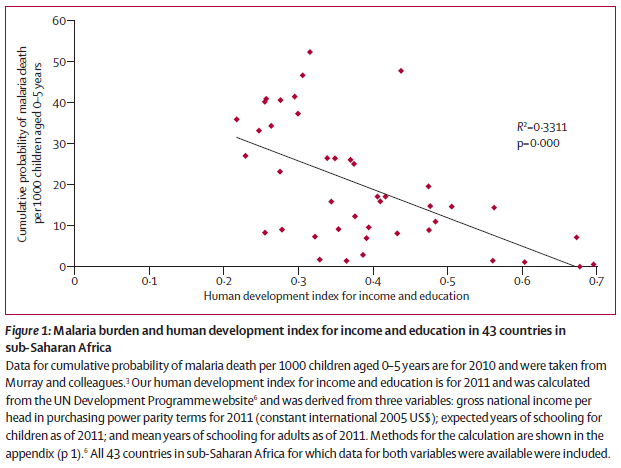
I wonder if the forest plot is here to stay?

It presents a lot of information, but maybe it could emphasize the important parts more. There is great benefit to having a standard way to present systematic review data, however, so any changes need to be for huge benefit or just little tweaks.
Comments Off on Journal Club: Socioeconomic development as an intervention against malaria
Filed under global health
