
I’ve got a new paper up on the arxiv. David Wilson recently posted this joint work that was one of the last things I did during my post-doc at Microsoft. It hasn’t been applied to health metrics yet, but maybe it will be. Let me tell you the story:
A spanning tree is just what it sounds like, if you know that a tree is a graph with no cycles, and make a good guess that the spanning tree is a subgraph that is a tree “spans” all the vertices in the graph. Minimum cost spanning trees come up in some very practical optimization problems, like if you want to build a electricity network without wasting wires. It was in this exact context, designing an electricity network for Moravia, that the first algorithm for finding a minimum spanning tree was developed.

A Minimum Spanning Tree, from Wikipedia
The great thing about looking for a minimum spanning tree is that you don’t have to be sneaky to find it. If you repeatedly find the cheapest edge which does not create a cycle, and add that to your subgraph, then this greedy approach never goes wrong. When you can’t add any more edges, you have a minimum spanning tree. Set systems with this property have been so fun for people to study that they have an intimidating name, matroids. But don’t be intimidated, you can go a long way in matroids by doing a search-and-replace s/matroid/spanning tree/.
Frequently my goal in my theoretical math research was to take a practical problem, like the minimum spanning tree, and extract out something useless but beautiful. A result by my advisor from the 1980s was great inspiration in this regard. Suppose you have a complete graph on n vertices, and every edge has a random cost chosen uniformly from the interval [0,1]. If you want the minimum spanning tree in this graph, you can find it, just run the greedy algorithm. But it takes some work to run the greedy algorithm on really big graphs. Enough work that this is sometimes assigned as homework in an algorithms class. So if you want to know how the cost of the minimum spanning tree grows as 
And now I can tell you a little bit about the results in my new paper. In many practical applications, it is not enough to have a minimum spanning tree, you want a minimum spanning tree with some additional constraints. Like the depth (in hops) from the root of the tree to any leaf is less than some bound. This very nearly came up for me in an application to organic produce distribution: you want to truck the broccoli from the farms to the markets, and you don’t want to “cross-dock” the veggies more than 3 times. But I’m talking theory today. So say you’ve still got that complete graph on n vertices, with uniformly random edge weights, only now you don’t want the tree to have depth exceeding d. As 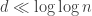
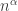
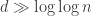

This is amazing combinatorial trivia, but there is also an important message. In addition to designing electrical networks, minimum spanning trees are used every day in machine learning for clustering. They are the key to the single linkage algorithm. There is a common problem with this clustering heuristic, however, which is the clusters are too “long and stringy”. I have high hopes that bounded depth single linkage clustering will be a useful heuristic for clustering things, maybe even in health metrics.
Oh, and that little problem, computational complexity. Finding a bounded depth minimum spanning tree is NP-hard for any depth between 2 and n – 1, but that doesn’t mean we should give up. For the uniformly random case in our paper, a simple heuristic is asymptotically optimal. And for more complicated cases, Alfredo Braunstein and Riccardo Zecchina and team have come up with a way to use belief propagation that has been very successful in experiments (and also predicts the threshold of 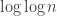

Pingback: ACO in Python: PADS for Minimum Spanning Trees « Healthy Algorithms
Pingback: The Two Rules of Debugging « Healthy Algorithms
The link to the message passing code doesn’t work anymore, but maybe it is still online somewhere. Meanwhile, I wrote about an MCMC based approach here (with movies).