
A short note on the PyMC mailing list alerted me that the Apeescape, the author of mind of a Markov chain blog, was thinking of using PyMC for replicating some controversial climate data analysis, but was having problems with it. Since I’m a sucker for controversial data, I decided to see if I could do the replication exercise in PyMC myself.
I didn’t dig in to what the climate-hockey-stick fuss is about, that’s something I’ll leave for my copious spare time. What I did do is find the data pretty easily available on the original author’s website, and make a translation of the R/bugs model into pymc/python. My work is all in a github repository if you want to try it yourself, here.
Based on Apeescape’s bugs model, I want to have 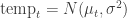
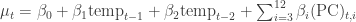


I implemented this in a satisfyingly concise 21 lines of code, that also generate posterior predictive values for model validation:
# load data
data = csv2rec('BUGS_data.txt', delimiter='\t')
# define priors
beta = Normal('beta', mu=zeros(13), tau=.001, value=zeros(13))
sigma = Uniform('sigma', lower=0., upper=100., value=1.)
# define predictions
pc = array([data['pc%d'%(ii+1)] for ii in range(10)]) # copy pc data into an array for speed & convenience
@deterministic
def mu(beta=beta, temp1=data.lagy1, temp2=data.lagy2, pc=pc):
return beta[0] + beta[1]*temp1 + beta[2]*temp2 + dot(beta[3:], pc)
@deterministic
def predicted(mu=mu, sigma=sigma):
return rnormal(mu, sigma**-2.)
# define likelihood
@observed
def y(value=data.y, mu=mu, sigma=sigma):
return normal_like(value, mu, sigma**-2.)
Making an image out of this to match the r version got me stuck for a little bit, because the author snuck in a call to “Friedman’s SuperSmoother” in the plot generation code. That seems unnecessarily sneaky to me, especially after going through all the work of setting up a model with fully bayesian priors. Don’t you want to see the model output before running it through some highly complicated smoothing function? (The super-smoother supsmu is a “running lines smoother which chooses between three spans for the lines”, whatever that is.) In case you do, here it is, together with an alternative smoother I hacked together, since python has no super-smoother that I know of.

Since I have the posterior predictions handy, I plotted the median residuals against the median predicted temperature values. I think this shows that the error model is fitting the data pretty well:


p.s. if the PyMC trouble was in getting the dang thing installed, see these notes I made for myself on that topic: https://healthyalgorithms.wordpress.com/about/pythonpymc-setup/
Thanks. To be clear, I had problems with the installation, and not the program itself. I think at one time I had like 10 Pythons installed on my system 🙂 (yes i’m a newbie)
The story is not so much controversial since the graph could not be replicated, the problem is that the entire McShane and Wyner 2010 paper is pretty much a 3-part crap – first part is no science but denier context, second part is the only statistical work – but the authors are so incompetent in climate science stuff that they don’t realize that the very weak method they analyzed/criticized is not used by any climate scientis, and a 3rd part in which they use an even weaker reconstruction method to generate a very unconvincing result which actually looks far more like a hockey stick than the Mann result 🙂
See at
http://klimazwiebel.blogspot.com/2010/08/mcshane-and-wyner-on-climate.html
for the only scientific feedback in regard to that paper – everything else is denier crap scandal!
@apeescape: You’re welcome! 🙂 On my laptop python “just works”, but I’ve got two copies of it competing for my attention on a different computer that causes me continual headaches.
@Mac: It sounds like it is at least a little controversial then… too bad if all of the effort to develop and explain uncertainty quantification is being applied to a model that isn’t interesting to climate scientists. I just wanted to make sure they could use PyMC if they wanted to.
Pingback: 2010 in review | Healthy Algorithms