
The negative binomial distribution is cool. Sometimes I think that.
Sometimes I think it is more trouble than it’s worth, a complicated mess.
Today, both.
Wikipedia and PyMC parameterize it differently, and it is a source of continuing confusion for me, so I’m just going to write it out here and have my own reference. (Which will match with PyMC, I hope!)
The important thing about the negative binomial, as far as I’m concerned, is that it is like a Poisson distribution, but “over-dispersed”. That is to say that the standard deviation is not always the square root of the mean. So I’d like to parameterize it with a parameter 


The slightly less important, but still informative, thing about the negative binomial, as far as I’m concerned, is that the way it is like a Poisson distribution is very direct. A negative binomial is a Poisson that has a Gamma-distributed random variable for its rate. In other words (symbols?), 
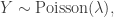

Unfortunately, nobody parameterizes the Gamma distribution this way. And so things get really confusing.
The way to get unconfused is to write out the distributions, although after they’re written, you might doubt me:
The negative binomial distribution is
and the Poisson distribution is
and the Gamma distribution is
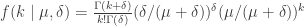


Hmm, does that help yet? If 


But instead of integrating it analytically (or in addition to), I am extra re-assured by seeing the results of a little PyMC model for this:

I put a notebook for making this plot in my pymc-examples repository. Love those notebooks. [pdf] [ipynb]

