
Cool project for teaching programming through web games: Play My Code

How to embed the game in the blog?
Cool project for teaching programming through web games: Play My Code
How to embed the game in the blog?
Comments Off on Code as Play
Filed under education
I learned last week about a Python Package for doing MCMC estimation, called PyMCMC. It sounds sort of like something I’m always writing about, doesn’t it?
From my quick look, it appears that pyMCMC has some advanced sampling methods (like Slice sampling) that are not yet implemented for PyMC. On the other hand, it seems like PyMC has a more flexible modeling language, which permits formulation of complex models without writing out likelihood functions explicitly.
Has anyone used PyMCMC? How did it go for you?
Comments Off on PyMC and PyMCMC
Filed under MCMC
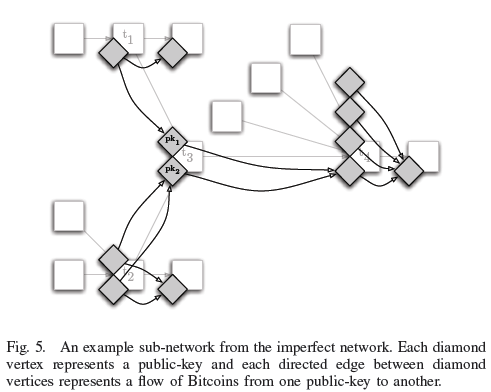 Bitcoin is intriguing, a digital currency where the entire transaction history of economy is held in common by all participants. I think that this will be a great observatory for research for someone. I read a recent paper that has some of the elements of this, An Analysis of Anonymity in the Bitcoin System by Fergal Reid and Martin Harrigan recently. As the name implies, it is mostly about the anonymity of the system. But it also includes a description of “the alleged theft of Bitcoins, which, at the time of the theft, had a market value of approximately half a million U.S. dollars”. That could be the plot of a good heist movie.
Bitcoin is intriguing, a digital currency where the entire transaction history of economy is held in common by all participants. I think that this will be a great observatory for research for someone. I read a recent paper that has some of the elements of this, An Analysis of Anonymity in the Bitcoin System by Fergal Reid and Martin Harrigan recently. As the name implies, it is mostly about the anonymity of the system. But it also includes a description of “the alleged theft of Bitcoins, which, at the time of the theft, had a market value of approximately half a million U.S. dollars”. That could be the plot of a good heist movie.
The paper led me to the bitcoin tools repository, which I’ll have to look into in more detail in the future.
Filed under Complex Networks
Two papers in the Arxiv caught my eye recently, (I have time to keep up on papers again!) both about networks and cooking. Both came out around Thanksgiving, too, but maybe that is just a coincidence.
Chun-Yuen Teng, Yu-Ru Lin, Lada A. Adamic, Recipe recommendation using ingredient networks
Yong-Yeol Ahn, Sebastian E. Ahnert, James P. Bagrow, Albert-László Barabási, Flavor network and the principles of food pairing
They both have wonderfully complex network graphics, although the lack of information in these beautiful figures is acknowledged:


I’d love to combine this sort of analysis with the work on nutritional risk factors that has been going on around here recently. Did either of these papers come with a dataset I can explore?
Filed under Complex Networks
Claire Mathieu has been blogging about intro math and CS videos from Khan Academy and from others:
I’ve heard about this Khan Academy, and it seems like more and more course material is appearing as tiny web videos.
Also I recently found out that there is a free, online version of the Stanford Intro AI Class taught by Peter Norvig and Sebastian Thrun, for which 56,000 students signed up. I think I accidentally did their homework.
Filed under education
Ben Birnbaum stood for his general exam last week, on a topic that I’m very interested in:
ABSTRACT–
Surveys are one of the principal means of gathering critical data from low-income regions. However, interviewer fabrication, or curbstoning, can threaten data quality. The existing literature lacks a set of general-purpose techniques to detect curbstoning; it does not capitalize on the potential of mobile data collection tools to help detect the phenomenon; and it provides few rigorous validations of the techniques that are developed. In this talk, I propose an anomaly detection framework to develop several general-purpose algorithms that identify curbstoning.
These algorithms can take advantage of the information in user traces from mobile data collection, a potential that I will evaluate rigorously. I also propose two studies to obtain high-quality labeled data sets with which I will validate my algorithms, thus partially filling the need for more rigorous evaluations.
Good job, Ben! Also in attendance was Aram Harrow, who was reminded of this great story of the lying professor. I wonder, could I could pull that off?
Comments Off on False information
Filed under education
 I read a short book about science and society last weekend, Unscientific America by Chris Mooney and Sheril Kirshenbaum. It’s a quick read, and the context is very much the 2008 elections, so you should browse it sooner than later. There are some good ideas, but the focus on web campaigns of 2008 are going to make them sound even more dated in a year.
I read a short book about science and society last weekend, Unscientific America by Chris Mooney and Sheril Kirshenbaum. It’s a quick read, and the context is very much the 2008 elections, so you should browse it sooner than later. There are some good ideas, but the focus on web campaigns of 2008 are going to make them sound even more dated in a year.
The book argues strongly for the meaningful popularization of scientific ideas. I love the popularizers of science, and was very influenced by books like Surely You’re Joking, Mr. Feynman and Gödel, Escher, Bach when I was a youth. The modern history sections in Unscientific America trace these popularizations to Carl Sagan’s book/television series Cosmos. I should check that out.
Filed under science policy
I’ve been thinking a lot about validating statistical models. My disease models are complicated, there are many places to make a little mistake. And people care about the numbers, so they will care if I make mistakes. My concern is grounded in experience; when I was re-implementing my disease modeling system, I realized that I mis-parameterized a bit of the model, giving undue influence to observations with small sample size. Good thing I caught it before anything was published based on the resultsI published anything based on the results!
How do I avoid this trouble going forwards? A well-timed blog post from Statistical Modeling, Causal Inference, and Social Science highlights one way, described in a paper linked there. I like this and I partially replicated in PyMC. But I’m concerned about something, which the authors mention in their conclusion:
To help ensure that errors, when present, are apparent from the simulation results, we caution against using “nice” numbers for fixed inputs or “balanced” dimensions in these simulations. For example, consider a generic hyperprior scale parameter s. If software were incorrectly written to use s^2 instead of s, the software could still appear to work correctly if tested with the fixed value of s set to 1 (or very close to 1), but would not work correctly for other values of s.
How do I avoid nice numbers in practice? I have an idea, but I’m not sure I like it. Does anyone else have ideas?
Also, my replication only works part of the time for my simple example, I guess because one of my errors is not enough of an error:



Comments Off on Validating Statistical Models
Filed under MCMC, software engineering
This NSF Program Solicitation crossed my desk recently. It is for “Smart Health and Wellbeing”, which includes a lot of healthy algorithms topic in the “new tools and methods” it lists. For example:
From Data to Knowledge to Decisions: Investigate methods and algorithms for aggregation of multi-scale clinical, biomedical, contextual, and environmental data about each patient (EHR, personal health records – PHR, etc.), and unified and extensible metadata standards, and decision support tools to facilitate optimized patient-centered evidence-based decisions. Integrate patient information with delivery systems performance and economic models to support operations management decisions. Develop robust knowledge representations and reasoning algorithms to support inferences based on individual or population health data, multiple sources of potentially conflicting information while complying with applicable policies and preferences. Develop innovative technology for the secondary use of health data to support assisted and automated discovery of reliable knowledge from aggregated population health records and predictive modeling and simulation of health and disease at multiple levels from cellular to individuals/patients to populations, along with robust validation and integration of empirical data into the models. Develop understanding of how families, communities, informal caregivers, professional medical teams and patients interpret care and treatment. Increase understanding of issues (technological, behavioral, socio-economic, value-driven actions, ethical, systemic) that interfere with patients’ collaboration in care team and adherence to treatment and wellness regimens.
Comments Off on NSF Program Solicitation for Smart Health
Filed under Uncategorized
