
I was looking for a quote that was the topic of my last post, and I found it in the resources list for this very interesting organization, The Public Science Project. They have a 14 minutes video about their work which I recommend:
While searching for that Tukey quote
Comments Off on While searching for that Tukey quote
Filed under education
Tukey quote I half-remembered
I was trying to remember some quote by the exploratory data analysis master John Tukey yesterday, and I think this is it:
No catalog of techniques can convey a willingness to look for what can be seen, whether or not anticipated. Yet this is at the heart of exploratory data analysis. The graph paper—and transparencies—are there, not as a technique, but rather as a recognition that the picture-examining eye is the best finder we have of the wholly unanticipated.
It is from John W. Tukey, We Need Both Exploratory and Confirmatory, The American Statistician, Vol. 34, No. 1 (Feb., 1980), pp. 23-25.
I remembered a version about the visual cortex as a the most advance signal processing device, so maybe there is another version of this out there.
Comments Off on Tukey quote I half-remembered
Filed under statistics
Automated Quality Assurance for Mobile Data Collection
I’m excited to call your attention to a paper that my co-author Ben Birnbaum is presenting next week at the ACM DEV conference:
- Benjamin Birnbaum, Brian DeRenzi, Abraham D. Flaxman, and Neal Lesh, Automated Quality Assurance for Mobile Data Collection
This research is about… well, the title says it pretty clearly. I’m interested in using our approach to detect surprises in data quality in all kinds of settings. Ben did the heavy lifting for this paper, so he deserves a lot of the congratulations that it has received the best paper award from the DEV 2012 program committee.
Congratulations, Ben!

Comments Off on Automated Quality Assurance for Mobile Data Collection
Filed under global health
MCMC in Python: A random effects logistic regression example
I have had this idea for a while, to go through the examples from the OpenBUGS webpage and port them to PyMC, so that I can be sure I’m not going much slower than I could be, and so that people can compare MCMC samplers “apples-to-apples”. But its easy to have ideas. Acting on them takes more time.
So I’m happy that I finally found a little time to sit with Kyle Foreman and get started. We ported one example over, the “seeds” random effects logistic regression. It is a nice little example, and it also gave me a chance to put something in the ipython notebook, which I continue to think is a great way to share code.




Filed under MCMC, software engineering
Cool Tool
Here is a web tool that recently crossed my desk, an interactive map on the human cost of mountaintop removal. It is a mashup of a bunch of different data sources, all on a Google map, that all say it is not healthy to live near a mountaintop removal coal mine.

Comments Off on Cool Tool
Filed under global health
Powell’s Method for Maximization in PyMC
I have been using “Powell’s Method” to find maximum likelihood (ahem, maximum a posteriori) estimates in my PyMC models for years now. It is something that I arrived at by trying all the options once, and it seemed to work most reliably. But what does it do? I never bothered to figure out, until today.
It does something very reasonable. That is to optimize a multidimensional function along one dimension at a time. And it does something very tricky, which is to update the basis for one-dimensional optimization periodically, so that it quickly finds a “good” set of dimensions to optimize over. Now that sounds familiar, doesn’t it? It is definitely the same kind of trick that makes the Adaptive Metropolis step method a winner in MCMC.
The 48-year-old paper introducing the approach, M. J. D. Powell, An efficient method for finding the minimum of a function of several variables without calculating derivatives, is quite readable today. If you want to see it in action, I added an ipython notebook to my pymc examples repository on github: [ipynb] [py] [pdf].

Comments Off on Powell’s Method for Maximization in PyMC
Filed under Uncategorized
Parameterizing Negative Binomial distributions
The negative binomial distribution is cool. Sometimes I think that.
Sometimes I think it is more trouble than it’s worth, a complicated mess.
Today, both.
Wikipedia and PyMC parameterize it differently, and it is a source of continuing confusion for me, so I’m just going to write it out here and have my own reference. (Which will match with PyMC, I hope!)
The important thing about the negative binomial, as far as I’m concerned, is that it is like a Poisson distribution, but “over-dispersed”. That is to say that the standard deviation is not always the square root of the mean. So I’d like to parameterize it with a parameter 


The slightly less important, but still informative, thing about the negative binomial, as far as I’m concerned, is that the way it is like a Poisson distribution is very direct. A negative binomial is a Poisson that has a Gamma-distributed random variable for its rate. In other words (symbols?), 
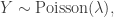

Unfortunately, nobody parameterizes the Gamma distribution this way. And so things get really confusing.
The way to get unconfused is to write out the distributions, although after they’re written, you might doubt me:
The negative binomial distribution is
and the Poisson distribution is
and the Gamma distribution is
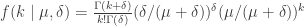


Hmm, does that help yet? If 


But instead of integrating it analytically (or in addition to), I am extra re-assured by seeing the results of a little PyMC model for this:

I put a notebook for making this plot in my pymc-examples repository. Love those notebooks. [pdf] [ipynb]
Filed under statistics
PyMC+Pandas: Poisson Regression Example
When I was gushing about the python data package pandas, commenter Rafael S. Calsaverini asked about combining it with PyMC, the python MCMC package that I usually gush about. I had a few minutes free and gave it a try. And just for fun I gave it a try in the new ipython notebook. It works, but it could work even better. See attached:

Filed under MCMC, software engineering
My new favorite for pythonic data wrangling
I’ve written before about my search for the way to deal with data in python. It’s time to write again, though because I have a new favorite: pandas, the panel data package.
There is copious, and growing documentation for pandas, but it assumes a level of familiarity with python and numpy. I thought I’d write some little examples calculations that I’ve done with pandas recently to complement the real docs with some “recipes”. You don’t really need to know python to use these, let alone numpy.
To begin, here are the creation and subset routines in pandas that do the same work that my last foray into this subject accomplished with the rec_array:
import pandas
a = ['USA','USA','CAN']
b = [1,6,4]
c = [1990.1,2005.,1995.]
d = ['x','y','z']
df = pandas.DataFrame({'country': a, 'age': b, 'year': c, 'data': d})
This is cooler than a rec_array because you don’t have to dig in the docs for the constructor, and you can use a dictionary to name each column.
You can select the subset of data relevant to a particular country-year-age thusly:
df[(df['country']=='USA') & (df['age']==6) & (df['year']==2005)]
This is not as cool as a rec_array, because writing It’s good that I complained about my uncool df['age'] has more characters than df.age, but I feel churlish to complain about it.
df['age'] business, because I learned that df.age works, too, as long as you are using an up-to-date pandas.
More substantial recipe to come. Is there already a cookbook out there?
Filed under software engineering
Code as Play
Cool project for teaching programming through web games: Play My Code

How to embed the game in the blog?
Comments Off on Code as Play
Filed under education
