
A recent question on the PyMC mailing list inspired me to make a really inefficient version of the Naive Bayes classifier. Enjoy.
Tag Archives: MCMC
ML in Python: Naive Bayes the hard way
Comments Off on ML in Python: Naive Bayes the hard way
Filed under machine learning
Stan in IPython: reproducing 8 schools
Continuing my experiment using Stan in IPython, here is a notebook to do a bit of the eight schools example from the RStan Getting Started Guide.
Comments Off on Stan in IPython: reproducing 8 schools
Filed under software engineering
Stan in IPython: getting starting
There has been a low murmur about new MCMC package bouncing through my email inbox for a while now. Stan, it is. The project has reached the point where the developers are soliciting Python integration volunteers, so I decided it is time to check it out.
Good news, it installed and ran the example without frustration! I don’t take that for granted with research software.
Comments Off on Stan in IPython: getting starting
Filed under software engineering
MCMC in Python: Bayesian meta-analysis example
In slow progress on my plan to to go through the examples from the OpenBUGS webpage and port them to PyMC, I offer you now Blockers, a random effects meta-analysis of clinical trials.

…

Filed under MCMC, software engineering
MCMC in Python: A random effects logistic regression example
I have had this idea for a while, to go through the examples from the OpenBUGS webpage and port them to PyMC, so that I can be sure I’m not going much slower than I could be, and so that people can compare MCMC samplers “apples-to-apples”. But its easy to have ideas. Acting on them takes more time.
So I’m happy that I finally found a little time to sit with Kyle Foreman and get started. We ported one example over, the “seeds” random effects logistic regression. It is a nice little example, and it also gave me a chance to put something in the ipython notebook, which I continue to think is a great way to share code.




Filed under MCMC, software engineering
PyMC at SciPy 2011
I just returned from the SciPy 2011 conference in Austin. Definitely a different experience than a theory conference, and definitely different than the mega-conferences I’ve found myself at lately. I think I like it. My goal was to evangelize for PyMC a little bit, and I think that went successfully. I even got to meet PyMC founder Chris Fonnesbeck in person (about 30 seconds before we presented a 4 hour tutorial together).
For the tutorial, I put together a set of PyMC-by-Example slides and code to dig into that silly relationship between Human Development Index and Total Fertility Rate that foiled my best attempts at Bayesian model selection so long ago.
I’m not sure the slides stand on their own, but together with the code samples they should reproduce my portion of the talk pretty well. I even started writing it up for people who want to read it in paper form, but then I ran out of momentum. Patches welcome.
Comments Off on PyMC at SciPy 2011
Filed under education, global health, MCMC, statistics
My First Contribution to PyMC
I’m excited to report that my first contribution back to the PyMC codebase was accepted. 🙂
It is a slight reworking of the pymc.Matplot.plot function that make it include autocorrelation plots of the trace, as well as histograms and timeseries. I also made the histogram look nicer (in my humble opinion).
Before:
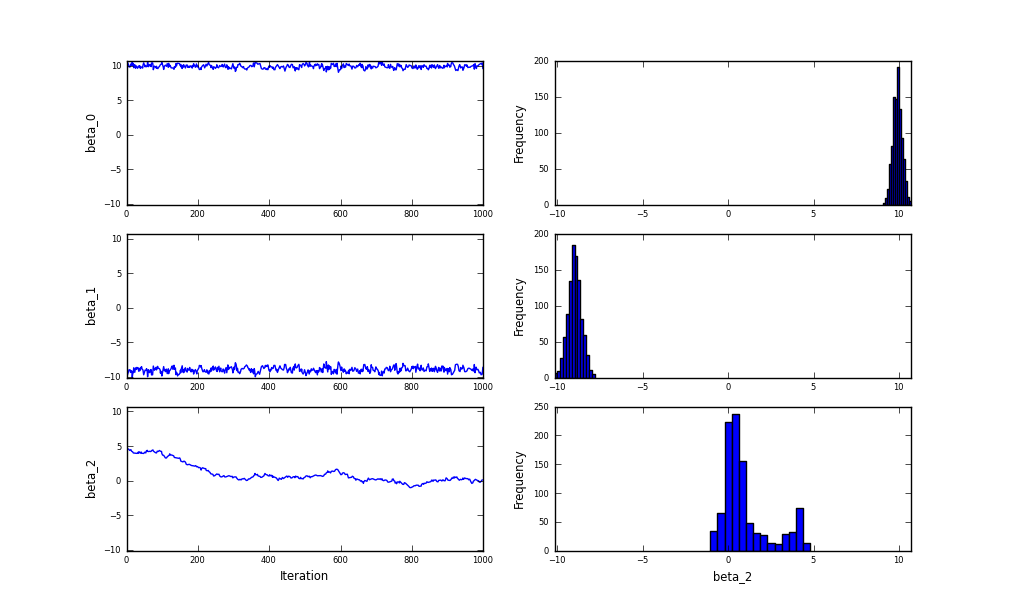
After:

In this example, I can tell that MCMC hasn’t converged from the trace of beta_2 without my changes, but it is dead obvious from the autocorrelation plot of beta_2 in the new version.
The process of making changes to the pymc sourcecode is something that has intimidated me for a while. Here are the steps in my workflow, in case it helps you get started doing this, too.
# first fork a copy of pymc from https://github.com/pymc-devs/pymc.git on github git clone https://github.com/pymc-devs/pymc.git # then use virtualenv to install it and make sure the tests work virtualenv env_pymc_dev source env_pymc_dev/bin/activate # then you can install pymc without being root cd pymc python setup.py install # so you can make changes to it without breaking everything else # to test that it is working cd .. python >>> import pymc >>> pymc.test() # then make changes to pymc... # to test changes, and make sure that all of the tests that use to pass still do repeat the process above cd pymc python setup.py install cd .. python >>> import pymc >>> pymc.test() # once everything is perfect, push it to a public git repo and send a "pull request" to the pymc developers.
Is there an easier way? Let me know in the comments.
Filed under MCMC, software engineering
MCMC in Python: A simple random effects model and its extensions
A nice example of using PyMC for multilevel (aka “Random Effects”) modeling came through on the PyMC mailing list a couple of weeks ago, and I’ve put it into a git repo so that I can play around with it a little, and collect up the feedback that the list generates.
Here is the situation:
Hi All,
New to this group and to PyMC (and mostly new to Python). In any case, I’m writing to ask for help in specifying a multilevel model (mixed model) for what I call partially clustered designs. An example of a partially clustered design is a 2-condition randomized psychotherapy study where subjects are randomly assigned to conditions. In condition 1, subjects are treated in small groups of say 8 people a piece. In the condition 2, usually a control, subjects are only assessed on the outcome (they don’t receive an intervention). Thus you have clustering in condition 1 but not condition 2.
The model for a 2-condition study looks like (just a single time point to keep things simpler):
where y_ij is the outcome for the ith person in cluster j (in most multilevel modeling software and in PROC MCMC in SAS, subjects in the unclustered condition are all in clusters of just 1 person), b_0 is the overall intercept, b_1 is the treatment effect, Tx is a dummy coded variable coded as 1 for the clustered condition and 0 for the unclustered condition, u_j is the random effect for cluster j, and e_ij is the residual error. The variance among clusters is \sigma^2_u and the residual term is \sigma^2_e (ideally you would estimate a unique residual by condition).Because u_j interacts with Tx, the random effect is only contributes to the clustered condition.
In my PyMC model, I expressed the model in matrix form – I find it easier to deal with especially for dealing with the cluster effects. Namely:
where X is an n x 2 design matrix for the overall intercept and intervention effect, B is a 1 x 2 matrix of regression coefficients, Z is an n x c design matrix for the cluster effects (where c is equal to the number of clusters in the clustered condition), and U is a c x 1 matrix of cluster effects. The way I’ve written the model below, I have R as an n x n diagonal matrix with \sigma^2_e on the diagonal and 0’s on the off-diagonal.All priors below are based on a model fit in PROC MCMC in SAS. I’m trying to replicate the analyses in PyMC so I don’t want to change the priors.
The data consist of 200 total subjects. 100 in the clustered condition and 100 in the unclustered. In the clustered condition there are 10 clusters of 10 people each. There is a single outcome variable.
I have 3 specific questions about the model:
- Given the description of the model, have I successfully specified the model? The results are quite similar to PROC MCMC, though the cluster variance (\sigma^2_u) differs more than I would expect due to Monte Carlo error. The differences make me wonder if I haven’t got it quite right in PyMC.
- Is there a better (or more efficient) way to set up the model? The model runs quickly but I am trying to learn Python and to get better at optimizing how to set up models (especially multilevel models).
- How can change my specification so that I can estimate unique residual variances for clustered and unclustered conditions? Right now I’ve estimated just a single residual variance. But I typically want separate estimates for the residual variances per intervention condition.

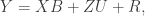
Here are my first responses:
1. This code worked for me without any modification. 🙂 Although when
I tried to run it twice in the same ipython session, it gave me
strange complaints. (for pymc version 2.1alpha, wall time 78s).
For the newest version in the git repo (pymc version 2.2grad,
commit ca77b7aa28c75f6d0e8172dd1f1c3f2cf7358135, wall time 75s) it
didn’t complain.
2. I find the data wrangling section of the model quite opaque. If
there is a difference between the PROC MCMC and PyMC results, this
is the first place I would look. I’ve been searching for the most
transparent ways to deal with data in Python, so I can share some
of my findings as applied to this block of code.
3. The model could probably be faster. This is the time for me to
recall the two cardinal rules of program optimization: 1) Don’t
Optimize, and 2) (for experts only) Don’t Optimize Yet.
That said, the biggest change to the time PyMC takes to run is in
the step methods. But adjusting this is a delicate operation.
More on this to follow.
4. Changing the specification is the true power of the PyMC approach,
and why this is worth the extra effort, since a random effects
model like yours is one line of STATA. So I’d like to write out
in detail how to change it. More on this to follow.
5. Indentation should be 4 spaces. Diverging from this inane detail
will make python people itchy.
Have a look in the revision history and the git repo README for more.
Good times. Here is my final note from the time I spent messing around:
Django and Rails have gotten a lot of mileage out of emphasizing
_convention_ in frequently performed tasks, and I think that PyMC
models could also benefit from this approach. I’m sure I can’t
develop our conventions myself, but I have changed all the file names
to move towards what I think we might want them to look like. Commit
linked here.
My analyses often have these basic parts: data, model, fitting code,
graphics code. Maybe your do, too.
p.s. Scott and I have started making an automatic model translator, to generate models like this from the kind of concise specification that users of R and STATA are familiar with. More news on that in a future post.
Filed under MCMC, statistics
MCMC in Python: Part IIb of PyMC Step Methods and their pitfalls
Two weeks ago, I slapped together a post about the banana distribution and some of my new movies sampling from it. Today I’m going to explore the performance of MCMC with the Adaptive Metropolis step method when the banana dimension grows and it becomes more curvy.
To start things off, have a look at the banana model, as implemented for PyMC:
C_1 = pl.ones(dim)
C_1[0] = 100.
X = mc.Uninformative('X', value=pl.zeros(dim))
def banana_like(X, tau, b):
phi_X = pl.copy(X)
phi_X *= 30. # rescale X to match scale of other models
phi_X[1] = phi_X[1] + b*phi_X[0]**2 - 100*b
return mc.normal_like(phi_X, 0., tau)
@mc.potential
def banana(X=X, tau=C_1**-1, b=b):
return banana_like(X, tau, b)
Pretty simple stuff, right? This is a pattern that I find myself using a lot, an uninformative stochastic variable that has the intended distribution implemented as a potential. If I understand correctly, it is something that you can’t do easily with BUGS.
Adaptive Metropolis is (or was) the default step method that PyMC uses to fit a model like this, and you can ensure that it is used (and fiddle with the AM parameters) with the use_step_method() function:
mod.use_step_method(mc.AdaptiveMetropolis, mod.X)
Important Tip: If you want to experiment with different step methods, you need to call mod.use_step_method() before doing any sampling. When you call mod.sample(), any stochastics without step methods assigned are given the method that PyMC deems best, and after they are assigned, use_step_method adds additional methods, but doesn’t remove the automatically added ones. (See this discussion from PyMC mailing list.)
So let’s see how this Adaptive Metropolis performs on a flattened banana as the dimension increases:
You can tell what dimension the banana lives in by counting up the panels in the autocorrelation plots in the upper right of each video, 2, 4 or 8. Definitely AM is up to the challenge of sampling from an 8-dimensional “flattened banana”, but this is nothing more than an uncorrelated normal distribution that has been stretched along one axis, so the results shouldn’t impress anyone.
Here is what happens in a more curvy banana:
Now you can see the performance start to degrade. AM does just fine in a 2-d banana, but its going to need more time to sample appropriately from a 4-d one and even more for the 8-d. This is similar to the way a cross-diagonal region breaks AM, but a lot more like something that could come up in a routine statistical application.
For a serious stress test, I can curve the banana even more:
Now AM has trouble even with the two dimensional version.
I’ve had an idea to take this qualitative exploration and quantify it to do a real “experimental analysis of algorithms” -style analysis. Have you seen something like this already? I do have enough to do without making additional work for myself.
Comments Off on MCMC in Python: Part IIb of PyMC Step Methods and their pitfalls
Filed under statistics, TCS
MCMC in Python: Part II of PyMC Step Methods and their pitfalls
I had a good time with the first round of my Step Method Pitfalls: besides making some great movies, I got a tip on how to combine Hit-and-Run with Adaptive Metropolis (together they are “the H-RAM“, fitting since the approach was suggested by Aram). And even more important than getting the tip, I did enough of a proof-of-concept to inspire Anand to rewrite it in the correct PyMC style. H-RAM lives.
Enter the GHME, where I had a lot of good discussions about methods for metrics, and where Mariel Finucane told me that her stress test for new step methods is always the banana (from Haario, Saksman, Tamminen, Adaptive proposal distribution for random walk Metropolis algorithm, Computational Statistics 1999):
The non-linear banana-shaped distributions are constructed from the Gaussian ones by ‘twisting’ them as follows. Let f be
the density of the multivariate normal distributionwith the covariance again given by
. The density function of the ‘twisted’ Gaussian with the nonlinearity parameter
is given by
, where the function
.
It’s a good distribution, and it makes for a good movie.
More detailed explorations to follow. What do you want to see?
Filed under statistics, TCS
