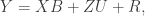The classic paper on the EM algorithm begins with a little application in multinomial modeling:
Rao (1965, pp. 368-369) presents data in which 197 animals are distributed multinomially into four categories, so that the observed data consist of
A genetic model for the population specifies cell probabilities
for some
with
.

Solving this analytically sounds very much like a 1960’s pastime to me (answer: 
import pymc as mc, numpy as np
pi = mc.Uniform('pi', 0, 1)
y = mc.Multinomial('y', n=197,
p=[.5 + .25*pi, .25*(1-pi), .25*(1-pi), .25*pi],
value=[125, 18, 20, 34], observed=True)
mc.MAP([pi,y]).fit()
print pi.value
But the point is to warm-up, not to innovate. The EM way is to introduce a latent variable 



import pymc as mc, numpy as np
pi = mc.Uniform('pi', 0, 1)
@mc.stochastic
def x(n=197, p=[.5, .25*pi, .25*(1-pi), .25*(1-pi), .25*pi], value=[125.,0.,18.,20.,34.]):
return mc.multinomial_like(np.round_(value), n, p)
@mc.observed
def y(x=x, value=[125, 18, 20, 34]):
if np.allclose([x[0]+x[1], x[2], x[3], x[4]], value):
return 0
else:
return -np.inf
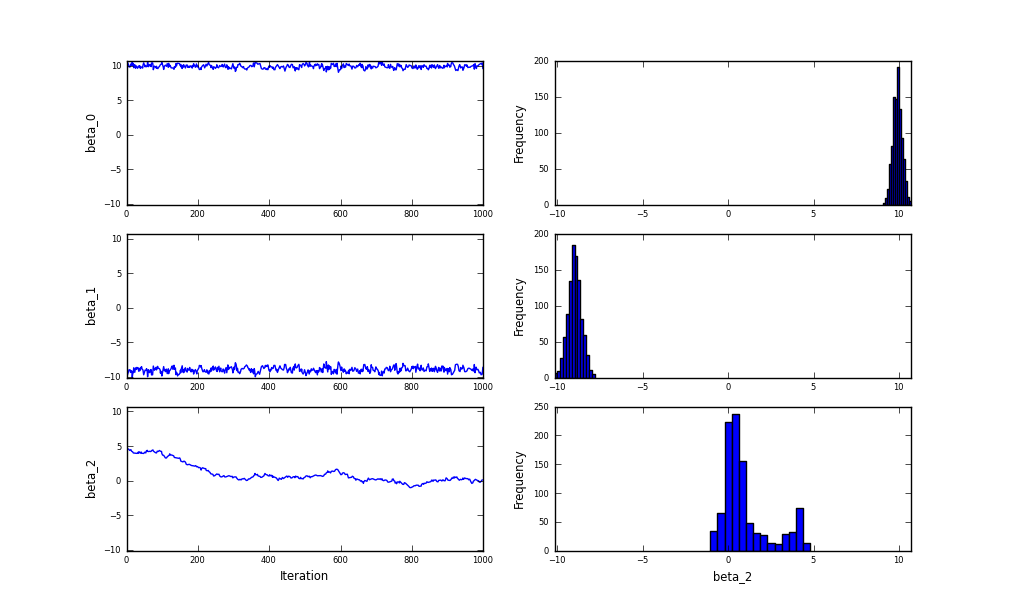
It is no longer possible to get a good fit to an mc.MAP object for this model (why?), but EM does not need to. The EM approach is to alternate between two steps:
- Update
- Update
This is simply implemented in PyMC and quick to get the goods:
def E_step():
x.value = [125 * .5 / (.5 + .25*pi.value), 125 * .25*pi.value / (.5 + .25*pi.value), 18, 20, 34]
def M_step():
pi.value = (x.value[1] + 34.) / (x.value[1] + 34. + 18. + 20.)
for i in range(5):
print 'iter %2d: pi=%0.4f, X=%s' %(i, pi.value, x.value)
E_step()
M_step()
It is not fair to compare speeds without making both run to the same tolerance, but when that is added EM is 2.5 times faster. That could be important sometimes, I suppose.







 for the mean and
for the mean and  for the dispersion. This is almost what PyMC does, except it calls the dispersion parameter
for the dispersion. This is almost what PyMC does, except it calls the dispersion parameter  instead of
instead of  is just shorthand for
is just shorthand for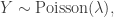

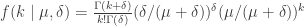


 and
and  , it all works out:
, it all works out: