Last month I attended a CNSTAT workshop https://sites.nationalacademies.org/DBASSE/CNSTAT/DBASSE_196518 on differentially private (DP) census data and left thinking that I need to get more hands-on experience with non-negative least squares optimization.
In the DP approach to disclosure avoidance that Census Bureau is planning, there is a “post-processing” step that improves the acceptability of imprecise DP counts of the number of individuals in a subgroup, like the voting age males who are non-Hispanic whites in King County census tract 89 http://ihmeuw.org/50cg. This improvement relies on non-negative least squares optimization. It finds fractional counts that sum to a known control total, that are not negative, and that minimize the sum of squared differences between these optimized counts and the DP imprecise counts. Sam Petti and I wrote out the details here, https://gatesopenresearch.org/articles/3-1722/v1 if you want to know more about this.
This blog is not about the DP details, but about how, in practice, I might try doing this sort of optimization. As anyone who has a PhD in Algorithms, Combinatorics, and Optimization can tell you, this sort of constrained convex optimization can be computed efficiently, meaning in time that scales like a polynomial function of the size of the instance. But when I was leaving graduate school, good luck if you wanted to actually solve a specific instance.
So I am quite pleased now to see how open-source software is making it possible today.
Ipopt https://github.com/coin-or/Ipopt#ipopt is an open-source interior point solver that can handle a quadratic objective function with linear equality and inequality constraints. My colleague Brad Bell has been a far of it for a decade, but until now I’ve just used it indirectly through his code.
Pyomo https://github.com/Pyomo/pyomo#pyomo-overview is a pythonic interface for many optimization solvers, including Ipopt, and now that I want to do something without Brad’s help, I’m glad to have it.
Here is a stripped down version of the optimization I want to do
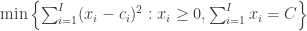
I’m completely dedicated to the Anaconda python distribution at this point (as setup and used in Software Carpentry), and if you are using this approach you can get everything you need to do such an optimization with the following
conda install -c conda-forge pyomo ipopt
You can test if this is working by executing the following little snippet of code in an IPython shell or Jupyter Notebook:
from pyomo.core import *
from pyomo.opt import SolverFactory
m = ConcreteModel()
m.x = Var([1,2], within=NonNegativeReals)
m.objective = Objective(expr=m.x[1]**2 + m.x[2]**2)
m.constraint = Constraint(expr=m.x[1] + m.x[2] == 1)
solver = SolverFactory('ipopt')
results = solver.solve(m)
print('Optimal value of x:',
(value(m.x[1]), value(m.x[2])))
Here is a challenge, if you like such a thing: use this test and the nonnegative least squares formula above to make a function that takes a list of imprecise counts and a float for a control total, and returns the optimized (fractional) counts for them.
It does take a bit of fiddling to get the pyomo python right, and then there are plenty of options to Ipopt that might make the optimization work better in more complicated cases. I found the book Pyomo — Optimization Modeling in Python useful for the former (and a pdf from a talk entitled Pyomo Tutorial – OSTI.GOV a good substitute before I got my hands on the book). For the latter, I found an extensive webpage of Ipopt options gave me some good hints, especially when combined with web searching, which provided only some small utility on its own.)
It is so cool that this is now possible. Thanks to all who made it so, including some old friends who must have been working on this back when I was a summer intern at IBM.
And for readers who don’t like or don’t have time for the challenge of coding it up themselves (perhaps including myself a day or a year from now), here is a solution:
def nonnegative_optimize(imprecise_counts, control_total):
"""optimize the imprecise counts so that they sum to
the control total and are non-negative
Parameters
----------
imprecise_counts : list-like of floats
control_total : float
Results
-------
returns optimized_counts, which are close to imprecise
counts, but not negative, and match control total in
aggregate
"""
imprecise_counts = list(imprecise_counts)
model = ConcreteModel()
model.I = range(len(imprecise_counts))
model.x = Var(model.I, within=NonNegativeReals)
model.objective = Objective(
expr=sum((model.x[i] - imprecise_counts[i])**2
for i in model.I))
model.constraint = Constraint(
expr=summation(model.x) == control_total)
solver = SolverFactory('ipopt')
results = solver.solve(model)
optimized_counts = [value(model.x[i])
for i in model.I]
return optimized_counts
p.s. if you want to see what this looks like in action, or for convenience in replication efforts, find a Jupyter Notebook version of the code from this blog here: https://gist.github.com/aflaxman/d7b39fc8cd5805e344a66f9c9d16acf7



