
Continuing my experiment using Stan in IPython, here is a notebook to do a bit of the eight schools example from the RStan Getting Started Guide.
Category Archives: software engineering
Stan in IPython: reproducing 8 schools
Comments Off on Stan in IPython: reproducing 8 schools
Filed under software engineering
Stan in IPython: getting starting
There has been a low murmur about new MCMC package bouncing through my email inbox for a while now. Stan, it is. The project has reached the point where the developers are soliciting Python integration volunteers, so I decided it is time to check it out.
Good news, it installed and ran the example without frustration! I don’t take that for granted with research software.
Comments Off on Stan in IPython: getting starting
Filed under software engineering
MCMC in Python: Bayesian meta-analysis example
In slow progress on my plan to to go through the examples from the OpenBUGS webpage and port them to PyMC, I offer you now Blockers, a random effects meta-analysis of clinical trials.

…

Filed under MCMC, software engineering
MCMC in Python: A random effects logistic regression example
I have had this idea for a while, to go through the examples from the OpenBUGS webpage and port them to PyMC, so that I can be sure I’m not going much slower than I could be, and so that people can compare MCMC samplers “apples-to-apples”. But its easy to have ideas. Acting on them takes more time.
So I’m happy that I finally found a little time to sit with Kyle Foreman and get started. We ported one example over, the “seeds” random effects logistic regression. It is a nice little example, and it also gave me a chance to put something in the ipython notebook, which I continue to think is a great way to share code.




Filed under MCMC, software engineering
PyMC+Pandas: Poisson Regression Example
When I was gushing about the python data package pandas, commenter Rafael S. Calsaverini asked about combining it with PyMC, the python MCMC package that I usually gush about. I had a few minutes free and gave it a try. And just for fun I gave it a try in the new ipython notebook. It works, but it could work even better. See attached:

Filed under MCMC, software engineering
My new favorite for pythonic data wrangling
I’ve written before about my search for the way to deal with data in python. It’s time to write again, though because I have a new favorite: pandas, the panel data package.
There is copious, and growing documentation for pandas, but it assumes a level of familiarity with python and numpy. I thought I’d write some little examples calculations that I’ve done with pandas recently to complement the real docs with some “recipes”. You don’t really need to know python to use these, let alone numpy.
To begin, here are the creation and subset routines in pandas that do the same work that my last foray into this subject accomplished with the rec_array:
import pandas
a = ['USA','USA','CAN']
b = [1,6,4]
c = [1990.1,2005.,1995.]
d = ['x','y','z']
df = pandas.DataFrame({'country': a, 'age': b, 'year': c, 'data': d})
This is cooler than a rec_array because you don’t have to dig in the docs for the constructor, and you can use a dictionary to name each column.
You can select the subset of data relevant to a particular country-year-age thusly:
df[(df['country']=='USA') & (df['age']==6) & (df['year']==2005)]
This is not as cool as a rec_array, because writing It’s good that I complained about my uncool df['age'] has more characters than df.age, but I feel churlish to complain about it.
df['age'] business, because I learned that df.age works, too, as long as you are using an up-to-date pandas.
More substantial recipe to come. Is there already a cookbook out there?
Filed under software engineering
Validating Statistical Models
I’ve been thinking a lot about validating statistical models. My disease models are complicated, there are many places to make a little mistake. And people care about the numbers, so they will care if I make mistakes. My concern is grounded in experience; when I was re-implementing my disease modeling system, I realized that I mis-parameterized a bit of the model, giving undue influence to observations with small sample size. Good thing I caught it before anything was published based on the resultsI published anything based on the results!
How do I avoid this trouble going forwards? A well-timed blog post from Statistical Modeling, Causal Inference, and Social Science highlights one way, described in a paper linked there. I like this and I partially replicated in PyMC. But I’m concerned about something, which the authors mention in their conclusion:
To help ensure that errors, when present, are apparent from the simulation results, we caution against using “nice” numbers for fixed inputs or “balanced” dimensions in these simulations. For example, consider a generic hyperprior scale parameter s. If software were incorrectly written to use s^2 instead of s, the software could still appear to work correctly if tested with the fixed value of s set to 1 (or very close to 1), but would not work correctly for other values of s.
How do I avoid nice numbers in practice? I have an idea, but I’m not sure I like it. Does anyone else have ideas?
Also, my replication only works part of the time for my simple example, I guess because one of my errors is not enough of an error:



Comments Off on Validating Statistical Models
Filed under MCMC, software engineering
Other Way Cool Demos from SciPy 2011
Besides the marvelous upgrade to ipython, there were some other things I saw at SciPy 2011 that I want to remember to remember.
I think I’ll have a lot more to say about Dexy soon, because I really need something like that. A tool to make documentation sexy. If only the tool itself had more documentation!
Filed under software engineering
Coolest Demo at SciPy 2011
Speaking of SciPy 2011 (as I was in my last post), the coolest, most draw-dropping-est demo I saw there was hands-down for the new ipython. The most cutting edge stuff is available on the web. I want it.
Filed under software engineering, Uncategorized
My First Contribution to PyMC
I’m excited to report that my first contribution back to the PyMC codebase was accepted. 🙂
It is a slight reworking of the pymc.Matplot.plot function that make it include autocorrelation plots of the trace, as well as histograms and timeseries. I also made the histogram look nicer (in my humble opinion).
Before:
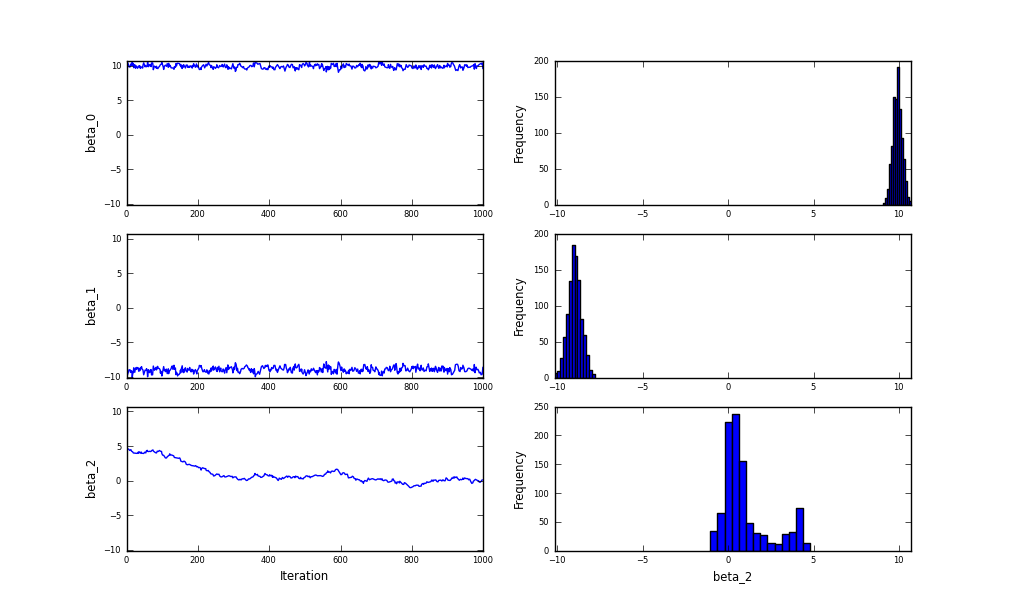
After:

In this example, I can tell that MCMC hasn’t converged from the trace of beta_2 without my changes, but it is dead obvious from the autocorrelation plot of beta_2 in the new version.
The process of making changes to the pymc sourcecode is something that has intimidated me for a while. Here are the steps in my workflow, in case it helps you get started doing this, too.
# first fork a copy of pymc from https://github.com/pymc-devs/pymc.git on github git clone https://github.com/pymc-devs/pymc.git # then use virtualenv to install it and make sure the tests work virtualenv env_pymc_dev source env_pymc_dev/bin/activate # then you can install pymc without being root cd pymc python setup.py install # so you can make changes to it without breaking everything else # to test that it is working cd .. python >>> import pymc >>> pymc.test() # then make changes to pymc... # to test changes, and make sure that all of the tests that use to pass still do repeat the process above cd pymc python setup.py install cd .. python >>> import pymc >>> pymc.test() # once everything is perfect, push it to a public git repo and send a "pull request" to the pymc developers.
Is there an easier way? Let me know in the comments.
Filed under MCMC, software engineering
