
20 seconds, 20 minutes, or 20 hours. These are all amounts of time that a computational method I’ve been working at some time has taken to complete processing. They each lead to a very different experience for the model developer, and probably in the end for the model, too. Twenty seconds is definitely what I prefer.
Computation time and model development
Comments Off on Computation time and model development
Filed under statistics, TCS
PBFs Summer
Just like last summer, many of the Post-Bachelors Fellows of IHME are away now to learn where global health metrics come from. Spencer James has a great photoblog from his work in Zambia. Are there other PBFs that I can follow from afar?

Comments Off on PBFs Summer
Filed under education
My First Contribution to PyMC
I’m excited to report that my first contribution back to the PyMC codebase was accepted. 🙂
It is a slight reworking of the pymc.Matplot.plot function that make it include autocorrelation plots of the trace, as well as histograms and timeseries. I also made the histogram look nicer (in my humble opinion).
Before:
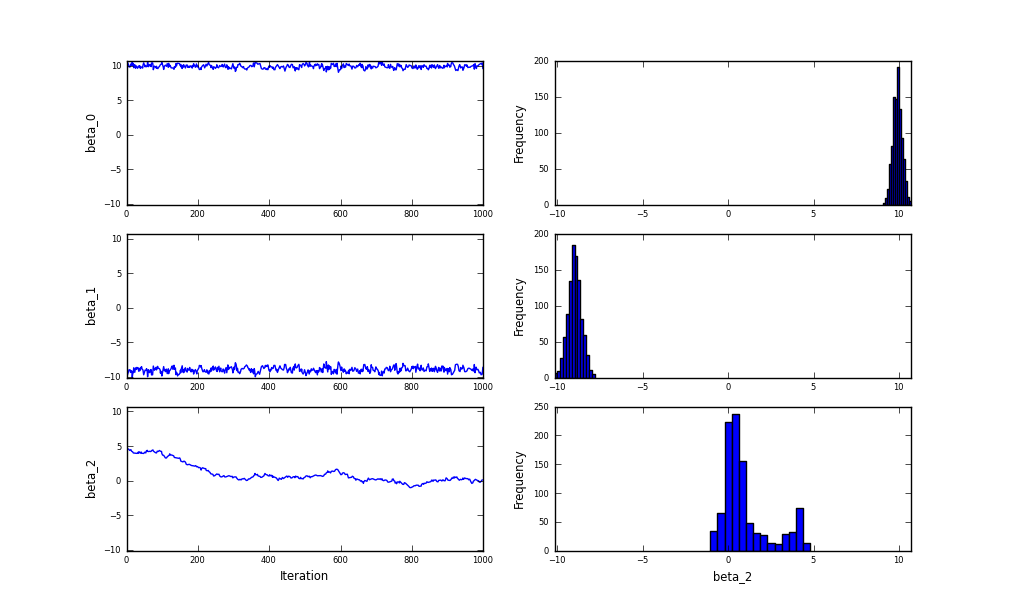
After:

In this example, I can tell that MCMC hasn’t converged from the trace of beta_2 without my changes, but it is dead obvious from the autocorrelation plot of beta_2 in the new version.
The process of making changes to the pymc sourcecode is something that has intimidated me for a while. Here are the steps in my workflow, in case it helps you get started doing this, too.
# first fork a copy of pymc from https://github.com/pymc-devs/pymc.git on github git clone https://github.com/pymc-devs/pymc.git # then use virtualenv to install it and make sure the tests work virtualenv env_pymc_dev source env_pymc_dev/bin/activate # then you can install pymc without being root cd pymc python setup.py install # so you can make changes to it without breaking everything else # to test that it is working cd .. python >>> import pymc >>> pymc.test() # then make changes to pymc... # to test changes, and make sure that all of the tests that use to pass still do repeat the process above cd pymc python setup.py install cd .. python >>> import pymc >>> pymc.test() # once everything is perfect, push it to a public git repo and send a "pull request" to the pymc developers.
Is there an easier way? Let me know in the comments.
Filed under MCMC, software engineering
Transparency in Global Health
Tom Paulson, the global health journalist behind the NPR blog Humanosphere, has been taking on some very non-transparent (opaque?) rules from the Pacific Health Summit here in Seattle. Fortunately, he took a break to laud the transparency with which the institute I’m working at operates. Maybe he thinks we can be an example for the summitteers, or at least a counter balance.
Paulson didn’t mention the aspect of IHME’s work which, as an ivory-tower inhabiting academic, I find most radically transparent, however. The journal Population Health Metrics, which IHME director Chris Murray is the co-editor-in-chief and big booster of, has a scarily open review process. It’s not just open publishing where everyone can read the papers, it’s so open that everyone can read the referee reports, and the responses to referees, and the whole chain of revisions that a paper goes through before being stamped peer-reviewed.
This is great for authors. As a referee, it makes me much more responsible for my actions, which takes longer, but is probably a good thing overall. I even put some PyMC code in a review once, to tell the authors how to do something the easy way. But now I’m not sure I want to go look at this correspondence after all.
Comments Off on Transparency in Global Health
Filed under science policy
Speaking of IE
Speaking of IE, which usually stands for Industrial Engineering, but at Cornell now stands for Information Engineering (or OR/MS, which stands for Operations Research/Management Sciences), there is a subdiscipline of global health that is going through a familiar search for the perfect name. It is actually somewhat related to OR/MS, definitely it would fit in at an INFORMS meeting. For a while was going to be called “Operational Research”, which I find confusing, since this is the old European name for Operations Research. But now it seems like they too want to have “science” in the name. The new contenders are “Implementation Science” and “Program Science”.
Any thoughts from veterans of the “OR/MS” naming process that I should share with my colleagues in a similar situation?
Comments Off on Speaking of IE
Filed under global health
IE Challenges in Global Health
I adapted my “Theoretical Computer Science Challenges in Global Health” for the UW Industrial Engineering department a couple of weeks ago. Instead of 10 minutes on noisy sorting for disability weight estimation, now it has 10 minutes stochastic optimization for disease control priorities. I consider it still a work in progress, but I do have a nice recording of the lecture if anyone wants some relaxing viewing:
Comments Off on IE Challenges in Global Health
Filed under global health
Wikipedia Editing for Scientists
David Eppstein has written up a guide for scientists who want to get started contributing to Wikipedia.
Here is why you might want to write for Wikipedia, from Eppstein’s writeup:
Why?
You already have other avenues for publishing your writing professionally, and plenty of demands on your time. Why should you take the extra time to write for Wikipedia as well?
- Public service. Part of being a scientist is communicating to the public, and Wikipedia is a great way of writing about research in a way that can be found and read by the public.
- Give and take. As a research scientist you are benefiting from a vast collection of survey articles written by the Wikipedia community. Why not reciprocate and help improve the existing articles by sharing your knowledge?
- Righting wrongs. You’ve probably already found some important topics that you know about from your research that are missing from Wikipedia, or worse, described incorrectly. Who better than someone who knows about these topics professionally to repair the damage?
- Practice. To write well on Wikipedia, you have to pay more attention to matters of readability than you might when writing for your peers. Practicing your writing ability in this way is likely to cause your professional writing to improve.
- Broaden your knowledge. When you write about a topic, you learn about it yourself; you may well find the topics you write about useful later in your own research. Also, when you carefully survey a topic, you are likely to find out about what is not known as well as what is known, and this could help you find future research projects.
- It looks good on your vita. Actually, I don’t think any tenure committee is going to care about your Wikipedia contributions. And in most cases the fact that you’ve contributed to an article is invisible to most readers, so it’s also not going to do much for making you more famous. But recently the NSF has started to take “broader impacts” more seriously on grant applications, and if you can make a convincing case that your Wikipedia editing activity is significant enough to count as a broader impact then that will probably improve your chances of getting funding. And getting more funding really does look good on your vita.
- Your advisor asked you to. This may or may not be a good reason, depending on what your advisor asked you to edit. Articles about a general subject area that you’re starting to learn about in your own research, as a way of making a public contribution while helping you learn: good. Articles about your advisor or his/her own research: not so good.
I agree.
Comments Off on Wikipedia Editing for Scientists
Filed under education
Life Expectancy by County in US
This recent study by my colleagues has been making headlines a lot last week, but I’m just getting to write about it now. While I was busy, stories about it appeared in high-profile outlets like NPR and the Statistical Modeling, Causal Inference, and Social Science blog.

As I’ve been thinking for two years (according to the ancient post I pushed out the door yesterday), life expectancy is a weird statistic. Life expectancy at birth is not, as the name might imply, a prediction on the average length of the life of a baby born this year. It is something more complicated to describe, but easier to predict. I like to think of it as the length of life if you froze the world exactly the way it is right now, and the baby today was exposed to the mortality risk of today’s one-year-olds next year, today’s two-year-olds in two years, etc. Although, as a friend pointed out two weeks ago, this is not a really good way to look at things either, if you push the analogy too hard. Currently Wikipedia isn’t really helpful on this matter, but maybe it will be better in the future.
There is another interesting thing in this paper, which is the validation approach the authors used. Unfortunately, it’s full development is in a paper still in press. Here is what they have to say about it so far:
We validated the performance of the model by creating small counties whose “true” underlying death rates were known. We did this by treating counties with large populations (> 750,000) as those where death rates have little sampling uncertainty. We then repeatedly sampled residents and deaths from these counties (by year and sex) to construct simulated small-county populations. We used the above model to predict mortality for these small, sampled-down counties, which were then compared with the mortality of the original large county.
I believe that this is fully developed in the paper which they cite at the beginning of the modeling section, Srebotnjak T, Mokdad AH, Murray CJL: A novel framework for validating and applying standardized small area measurement strategies, submitted. From what I’ve heard about it, I like it.
Comments Off on Life Expectancy by County in US
Filed under global health
What is life expectance?
Hint: It’s not what you think.
(This is a post that I never finished/barely started almost two years ago.)
Filed under Uncategorized
Age-heaping and Hedgehogs
I heard an interesting talk a few weeks ago about “age-heaping” in survey responses, the phenomenon where people remember ages imprecisely and say that their siblings are ages that are divisible by 5 much more often than expected. There are some nice theory challenges here, with a big dose of stats modeling, but I’ll have to share some more thoughts on that later.
In the talk, the age-heaping was also referred to a a hedgehog or porcupine plot, because of the spikey histogram that the data produces. I was looking for a nice picture of one, or some additional background reading, and when I searched for “hedgehog statistical plots”, all google would give me was a bunch of pages about stats on actual hedgehogs. Cute!
Filed under TCS
