
Have you heard me say that Verbal Autopsy is a exemplary machine learning challenge? I think I say it about once a week.
Now there’s going to be a great forum for saying it. Read more here.
Have you heard me say that Verbal Autopsy is a exemplary machine learning challenge? I think I say it about once a week.
Now there’s going to be a great forum for saying it. Read more here.
Comments Off on Global Congress on Verbal Autopsy in 2011 open for abstract submission
Filed under global health
A recent question on the PyMC mailing list inspired me. How can you estimate transition parameters in a compartmental model? I did a lit search for just this when I started up my generic disease modeling project two years ago. Much information, I did not find. I turned up one paper which said basically that using a Bayesian approach was a great idea and someone should try it (and I can’t even find that now!).
Part of the problem was language. I’ve since learned that micro-simulators call it “calibration” when you estimate parameter values, and there is a whole community of researchers working on “black-box modeling plug-and-play inference” that do something similar as well. These magic phrases are incantations to the search engines that help find some relevant prior work.
But I started blazing my own path before I learned any of the right words; with PyMC, it is relatively simple. Consider the classic SIR model from mathematical epidemology. It’s a great place to start, and it’s what Jason Andrews started with on the PyMC list. I’ll show you how to formulate it for Bayesian parameter estimation in PyMC, and how to make sure your MCMC has run for long enough. Continue reading
Filed under global health, MCMC, statistics
I was forwarded a recent article about the Gates Foundation and how it has partnered with news organizations like ABC News and The Guardian. And guess what? IHME makes an appearance in the second half of the second page! I wouldn’t say that it’s positive about my work, but I am delighted to see the technical appendix mentioned in print.
During my recent education in medicine, I’ve learned that an appendix is something that people think you don’t need. Also, if something goes wrong with it, it can kill you. And it’s true that the “webpendix” is 219 pages, but the bulk of that is pictures. The first 19 pages are a pretty decent stats paper about how we used Gaussian Processes to model really noisy time-series data.

Yearly percentage decline in mortality in children younger than 5 years between 1990 and 2010
Comments Off on IHME and a Gates Foundation Critique
Filed under global health
A couple of new papers on networks crossed my desk this week. Well, more than a couple, since I’m PC-ing for the Web Algorithms Workshop (WAW) right now. But a couple crossed my desk that I’m not reviewing, which means I can write about them.
Brendan Nyhan writes:
Just came across your blog post on Christakis/Fowler and the various critiques – thought this paper I just posted to arXiv with Hans Noel might also be of interest: The “Unfriending” Problem: The Consequences of Homophily in Friendship Retention for Causal Estimates of Social Influence
Unfriending is interesting, and an area that seems understudied. In online social networks, there is often no cost to keep a tie in place. The XBox Live friend network is not such a case: an XBox gamer sees frequent updates about their friends’ activities. That’s why I thought it made sense when I learned that the XBox Live social network does not exhibit the heavy tailed degree-distribution phenomenon that has been widely reported in real-world networks. Someone should talk Microsoft into releasing an anonymized edition of this graph (if such an anonymization is possible…).
Meanwhile, Anton Westveld and Peter Hoff’s paper on modeling longitudinal network data caught my eye on arxiv: A Mixed Effects Model for Longitudinal Relational and Network Data, with Applications to International Trade and Conflict.
All the things I’d like to read… I could write a book about it. Before I even had time to finish writing this post, I saw another one: On the Existence of the MLE for a Directed Random Graph Network Model with Reciprocation.
Filed under statistics
Here’s a great summary of how an evaluation of Washington D.C.’s open-source voting system found and fixed security flaws just the way the open-source lovers said it would: Hacking the D.C. Internet Voting Pilot.
Comments Off on Open Source for Voting gets the goods
Filed under Uncategorized
Jennifer Rexford’s advice for new grad students is also good for old grad students and new post-docs. See it on the Freedom to Tinker Blog.
Comments Off on Advice for new grad students
Filed under education
School is starting up, and I’m absolved of teaching duties for my first year as a prof. Very nice, but it is strange to see the trees turning towards fall without classes keeping me busy. I’m going to try to look over the shoulder of the new IHME students. They’re almost all taking an intro biostats course, which is stuff that I should know. I never took a class in it, so I suspect there are gaps in my knowledge… I don’t even know what I don’t know.
Meanwhile, in Colorado, Aaron Clauset is giving a class that I wish I had taken in grad school, Inference, Models and Simulation for Complex Systems. The reading list is full of things I like, so maybe I’ll pretend I’m still a student and read the ones I haven’t yet.
Comments Off on Fall Classes
Filed under education
I’ve been flipping through the titles of SODA acceptances listed on the blogs, and wondering if I’m losing touch with TCS research. It’s a good chance for me to think about what algorithms (discrete or otherwise) have been really big in the health metrics work I’ve been doing recently.
So I guess my research needs are not squarely within the SODA realm. But they are not disjoint from it either. I’m still touching theory, if not totally in touch. Maybe one day soon I’ll even have time to prove something.
Comments Off on Losing touch with theory?
Filed under TCS
It’s been a busy two weeks since I got back in town. The PBFs who went to “the field” for their summer abroad have returned with lots of fun and interesting stories. A new batch of PBFs and PGFs has arrived, bringing IHME to it’s planned capacity of around 100 heads. And I’ve been getting deeply into experimental analysis of a gaussian process regression technique, much like the one we used for estimating child mortality rates.
Maybe I’ll work on it publicly here on healthy algorithms. I’ll see if that seems too boring as I proceed.
For the moment, I’m just looking for reading suggestions. I was very inspired by David Johnson’s papaer A Theoretician’s Guide to the Experimental Analysis of Algorithms when I read it, but that was years ago. I’m going to have to read it again. What else do you recommend like this?
Filed under TCS
A short note on the PyMC mailing list alerted me that the Apeescape, the author of mind of a Markov chain blog, was thinking of using PyMC for replicating some controversial climate data analysis, but was having problems with it. Since I’m a sucker for controversial data, I decided to see if I could do the replication exercise in PyMC myself.
I didn’t dig in to what the climate-hockey-stick fuss is about, that’s something I’ll leave for my copious spare time. What I did do is find the data pretty easily available on the original author’s website, and make a translation of the R/bugs model into pymc/python. My work is all in a github repository if you want to try it yourself, here.
Based on Apeescape’s bugs model, I want to have 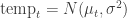
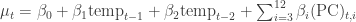


I implemented this in a satisfyingly concise 21 lines of code, that also generate posterior predictive values for model validation:
# load data
data = csv2rec('BUGS_data.txt', delimiter='\t')
# define priors
beta = Normal('beta', mu=zeros(13), tau=.001, value=zeros(13))
sigma = Uniform('sigma', lower=0., upper=100., value=1.)
# define predictions
pc = array([data['pc%d'%(ii+1)] for ii in range(10)]) # copy pc data into an array for speed & convenience
@deterministic
def mu(beta=beta, temp1=data.lagy1, temp2=data.lagy2, pc=pc):
return beta[0] + beta[1]*temp1 + beta[2]*temp2 + dot(beta[3:], pc)
@deterministic
def predicted(mu=mu, sigma=sigma):
return rnormal(mu, sigma**-2.)
# define likelihood
@observed
def y(value=data.y, mu=mu, sigma=sigma):
return normal_like(value, mu, sigma**-2.)
Making an image out of this to match the r version got me stuck for a little bit, because the author snuck in a call to “Friedman’s SuperSmoother” in the plot generation code. That seems unnecessarily sneaky to me, especially after going through all the work of setting up a model with fully bayesian priors. Don’t you want to see the model output before running it through some highly complicated smoothing function? (The super-smoother supsmu is a “running lines smoother which chooses between three spans for the lines”, whatever that is.) In case you do, here it is, together with an alternative smoother I hacked together, since python has no super-smoother that I know of.

Since I have the posterior predictions handy, I plotted the median residuals against the median predicted temperature values. I think this shows that the error model is fitting the data pretty well:

Filed under MCMC, statistics
