There is this paradox: federal budgets, and, particularly, what is allocated for science, is something so important day-to-day for researchers, yet reading about budgets is so boring that I can hardly bring myself to do it.
It is important, though, so we should try. The folks at ScienceNOW have done a nice summary of the effects of the “continuing resolution” which congress passed last weekend and Bush signed on Tuesday. What this means in dollars is that most all budget items stay the same as last year, except that there is also inflation, so, in real dollars the amount spent on all science decreases.
“I think the next Administration will be very leery of more spending given the current state of the economy,” speculates Samuel Rankin III, a lobbyist for the American Mathematical Society and head of the Coalition for National Science Funding.
For some science agencies, the CR actually puts them below the amounts spent this year. That’s because the legislators excluded the $400 million divvied up among NSF, DOE, NASA, and the National Institutes of Health (NIH) under a supplemental 2008 spending bill passed in June
Let’s not be all doom and gloom, though; Michael Mitzenmacher reports that enrollment in beginning CS at Harvard is up, up, up.
2 years ago — 132
1 year ago — 282
this year — 341


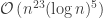 . The idea is this: you start with some point in S and try to move to a new, nearby point randomly. “Randomly how?”, you wonder. That is the art.
. The idea is this: you start with some point in S and try to move to a new, nearby point randomly. “Randomly how?”, you wonder. That is the art. 


