I’ve got some of my colleagues interested in using Python to cruch their numbers, and that’s great, because I’m sure it will make their lives much better in the long run. It’s also great because they are pushing me to figure out the easy way to do things, since they are used to certain conveniences from their past work with R and STATA.

For example, Kyle wanted to know does Python make it easy to deal with the tables of data he is faced with every day?
It was by showing my ignorance in a blog post a year ago that I learned about handing csv files with the csv.DictReader class. And this has been convenient enough for me, but it doesn’t let Kyle do the things the way he is used to, for example using data[[‘iso3’, ‘gdp’], :] to select these two important columns from a large table.
Enter larry, the labeled array. Maybe someone will tell me an even cleaner way to deal with these tables, but after a quick easy_install la, I was able to load up some data from the National Cancer Institute (NCI) as follows:
import csv
import la
from pylab import *
csv_file = csv.reader(open('accstate5.txt'))
columns = csv_file.next()[1:]
rows = []
data = []
for d in csv_file:
rows.append(d[0])
data.append(d[1:])
T = la.larry(data, [rows, columns])
That’s pretty good, but the data is not properly coded as floating point…
T = la.larry(data, [rows, columns]).astype(float)
Now, T has the whole table, indexed by state and by strange NCI code
T.lix[['WA', 'OR', 'ID', 'MO'], ['RBM9094']]
Perfect, besides being slightly ugly. But is there an easier way? the la documentation mentions a fromcsv method. Unfortunately la.larry.fromcsv doesn’t like these short-format tables.
la.larry.fromcsv('accstate5.txt') # produces a strange error
Now, if you read the NCI data download info page, where I retrieved this data from, you will learn what each cryptic column heading means:
Column heading format: [V] [RG] [T] [A], where
V = variable: R, C, LB, or UB
RG = race / gender: BM, BF, WM, WF (B = black, W = white, F = female, M = male)
T = calendar time: 5094, 5069, 7094, and the 9 5-year periods 5054 through 9094
A = age group: blank (all ages), 019, 2049, 5074, 75+
Example:
RBM5054 = rate for black males for the time period 1950-1954
That means I’m not really dealing with a 2-dimensional table after all, and maybe I’d be better off organizing things the way they really
are:
data_dict_list = [d for d in csv.DictReader(open('accstate5.txt'))]
data_dict = {}
races = ['B', 'W']
sexes = ['M', 'F']
times = range(50,95,5)
for d in data_dict_list:
for race in races:
for sex in sexes:
for time in times:
key = 'R%s%s%d%d' % (race, sex, time, time+4)
val = float(d.get(key, nan)) # larry uses nan to denote missingdata
data_dict[(d['STATE'], race, sex, '19%s'%time)] = val
R = la.larry.fromdict(data_dict)
In the original 2-d labeled array we can compare cancer rates thusly:
states = ['OR', 'WA', 'ID', 'MT']
times = arange(50,94,5)
selected_cols = ['RWM%d%d' % (t, t+4) for t in times]
T_selected = T.lix[states, selected_cols]
plot(1900+times, T_selected.getx().T, 's-',
linewidth=3, markersize=15, alpha=.75)
legend(T_selected.getlabel(0), loc='lower right', numpoints=3, markerscale=.5)
ylabel('Mortality rate (per 100,000 person-years)')
xlabel('Time (years)')
title('Mortality rate for all cancers over time')
axis([1945, 1995, 0, 230])
It is slightly cooler to do the same plot with the multi-dimensional array
clf()
subplot(2,1,1)
times = [str(t) for t in range(1950, 1994, 5)]
states = ['OR', 'WA', 'ID', 'MT']
colors = ['c', 'b', 'r', 'g']
for state, color in zip(states, colors):
plot(R.getlabel(3), R.lix[[state], ['W'], ['M'], :].getx(), 's-', color=color,
linewidth=3, markersize=15, alpha=.75)
legend(T_selected.getlabel(0), loc='lower right', numpoints=3, markerscale=.5)
ylabel('Mortality rate (per 100,000 person-years)')
xlabel('Time (years)')
title('Mortality rate for all cancers in white males over time')
axis([1945, 1995, 0, 230])
That should be enough for me to remember how to use larry when I come back to it in the future. For my final trick, let’s explore how to use larrys to add a column to a 2-dimensional table. (There is some important extension of this to multidimensional tables, but it is confusing me a lot right now.)
states = T.getlabel(0)
X = la.larry(randn(len(states), 1), [states, ['new covariate']])
T = T.merge(X)
states = ['OR', 'WA', 'ID', 'MT']
T.lix[states, ['RWM9094', 'new covariate']]
Ok, encore… how well does larry play with PyMC? Let’s use a Gaussian Process model to find out.
from pymc import *
M = gp.Mean(lambda x, mu=R.mean(): mu * ones(len(x)))
C = gp.Covariance(gp.matern.euclidean, diff_degree=2., amp=1., scale=1.)
mesh = array([[i,j,k,.5*l] for i in range(52) for j in range(2) for k in range(2) for l in arange(9)])
obs_mesh = array([[i,j,k,.5*l] for i in range(52) for j in range(2) for k in range(2) for l in range(9) if not isnan(R[i,j,k,l])])
obs_vals = array([R[i,j,k,l] for i in range(52) for j in range(2) for k in range(2) for l in range(9) if not isnan(R[i,j,k,l])])
obs_V = array([1. for i in range(52) for j in range(2) for k in range(2) for l in range(9) if not isnan(R[i,j,k,l])])
gp.observe(M, C, obs_mesh, obs_vals, obs_V)
imputed_vals = M(mesh)
imputed_std = sqrt(abs(C(mesh)))
Ri = la.larry(imputed_vals.reshape(R.shape), R.label)
subplot(2,1,2)
for state, color in zip(states, colors):
t = [float(l) for l in Ri.getlabel(3)]
plot(t, R.lix[[state], ['B'], ['M'], :].getx(), '^', color=color, linewidth=3, markersize=15, alpha=.75)
plot(t, Ri.lix[[state], ['B'], ['M'], :].getx(), '-', color=color, linewidth=2, alpha=.75)
ylabel('Mortality rate (per 100,000 person-years)')
xlabel('Time (years)')
title('Mortality rate for all cancers in black males over time')
axis([1945, 1995, 0, 630])

 My first first-authored global health paper came out today (I consider it my first “first-authored” paper ever, since the mathematicians I’ve worked with deviantly list authorship in alphabetical order regardless of seniority and contribution). It’s a bit of a mouthful by title: Rapid Scaling Up of Insecticide-Treated Bed Net Coverage in Africa and Its Relationship with Development Assistance for Health: A Systematic Synthesis of Supply, Distribution, and Household Survey Data.
My first first-authored global health paper came out today (I consider it my first “first-authored” paper ever, since the mathematicians I’ve worked with deviantly list authorship in alphabetical order regardless of seniority and contribution). It’s a bit of a mouthful by title: Rapid Scaling Up of Insecticide-Treated Bed Net Coverage in Africa and Its Relationship with Development Assistance for Health: A Systematic Synthesis of Supply, Distribution, and Household Survey Data.
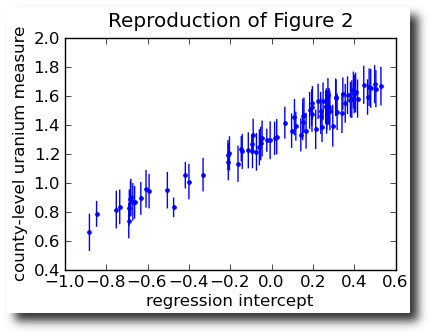



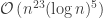 . The idea is this: you start with some point in S and try to move to a new, nearby point randomly. “Randomly how?”, you wonder. That is the art.
. The idea is this: you start with some point in S and try to move to a new, nearby point randomly. “Randomly how?”, you wonder. That is the art. 